
AWS Lambda(以降、Lambdaと呼びます。)は、そのサーバーレスアーキテクチャで高い柔軟性とスケーラビリティを提供しますが、コールドスタート問題がパフォーマンスに影響を与えることがあります。この問題に対処するため、AWSはLambdaのProvisioned Concurrencyを導入しました。本記事では、その仕組みと設定方法について詳しく解説するとともに、実際に手を動かしながらProvisioned Concurrencyを適用するハンズオンも紹介します。これにより、パフォーマンス向上の実践的な知識を得ることができます。
- はじめに:AWS LambdaとProvisioned Concurrencyの重要性を理解する
- Provisioned Concurrencyの仕組みを解説
- メリットとトレードオフ:Provisioned Concurrencyの効果とコストのバランス
- 具体的な使用シナリオ:Provisioned Concurrencyを活用すべき場面とは?
はじめに:AWS LambdaとProvisioned Concurrencyの重要性を理解する
Lambdaは、サーバー管理を不要にし、コードの実行に集中できるサーバーレスアーキテクチャを提供します。しかし、Lambdaには初回実行時にコールドスタートと呼ばれる遅延が発生する課題があります。この遅延は、特にリアルタイム処理やユーザー体験が重要なアプリケーションにおいて問題となり、APIエンドポイントなどへのリクエストが増加した際に、最初の応答が遅れることがあります。
この課題に対処するために登場するのがProvisioned Concurrencyです。Provisioned Concurrencyを利用することで、Lambda関数をあらかじめプロビジョニングし、常に即時実行可能な状態を維持できます。これにより、リクエストの遅延を最小限に抑え、ユーザー体験の向上につながります。
Provisioned Concurrencyは、高頻度で実行されるAPIやリアルタイム処理を行うアプリケーションに特に有効です。また、ビジネスにおいても、パフォーマンスが顧客満足度や売上に直結するシステムでは迅速な応答が求められるため、重要なツールとなります。
この記事では、Provisioned Concurrencyの仕組みと設定方法を詳しく解説し、実際にパフォーマンス向上をハンズオンで確認します。Lambdaのパフォーマンスを最大限に引き出し、システムのレスポンスを最適化するためのステップを解説します。
- Lambdaを使用しているが、コールドスタートによる遅延に悩んでいるエンジニア
- トラフィックの多いアプリケーションを運用しており、パフォーマンスを最適化したいエンジニア
- Provisioned Concurrencyの仕組みや利点を理解し、実際に導入したいアーキテクト
- サーバーレスアーキテクチャを活用して、コストとパフォーマンスのバランスを取る方法を学びたい技術者
- Provisioned Concurrencyを利用することで、コールドスタートの影響を最小限に抑える方法を理解できる
- Lambdaのパフォーマンスを向上させるための具体的な手順が分かる
- Provisioned Concurrencyの導入に伴うコストや効果を事前に把握できるため、最適な導入計画が立てられる
- 実際のプロジェクトで、トラフィックのピークに合わせたプロビジョニング設定を行い、システムの安定性を向上させることができる
Provisioned Concurrencyの仕組みを解説
Lambdaの強力な機能の一つであるProvisioned Concurrencyは、コールドスタートによる遅延を解消し、常に即時応答可能なLambda関数を維持するための仕組みです。本章では、このProvisioned Concurrencyの動作原理を解説し、どのようにLambda関数のパフォーマンスを改善するのか、具体的に解説します。
コールドスタートの問題とは?
Lambdaのコールドスタートは、関数が初めて実行される際や長時間アイドル状態だった後に発生する遅延を指します。リクエストが発生すると、Lambdaは実行環境を起動し、コードや依存ライブラリを読み込みます。この初期化プロセスに時間がかかるため、最初のリクエストに対する応答が遅れることがあります。
特に、リアルタイム応答が求められるアプリケーションにおいて、この遅延はユーザー体験に悪影響を与える可能性があります。たとえば、APIエンドポイントへの最初のリクエストやページの初回アクセス時にコールドスタートが発生すると、レスポンスが遅れ、パフォーマンス低下が顕著になります。
Lambda API 経由で関数を実行するリクエストを受け取ると、下記の順に実行します。
- サービスは関数のコードをダウンロード
- このコードは内部の S3 バケットまたは、Amazon ECRに保存されます。
- メモリ、ランタイム、および構成が指定された環境を作成
- Lambda はイベントハンドラーの外部で初期化コードを実行
- ハンドラーコードを実行します。
コールドスタートは、上記の最初の2つのステップを指しています。
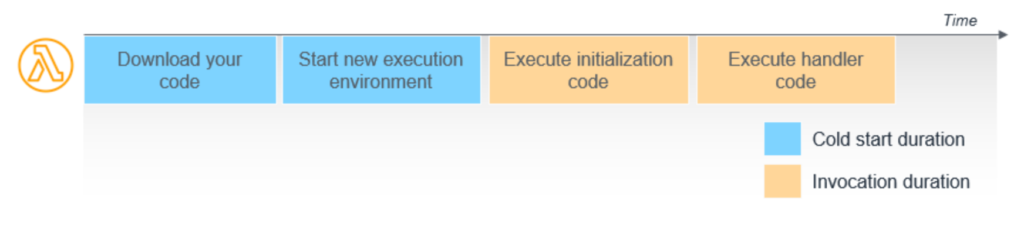
※ 出展:AWSドキュメント コールドスタートとレイテンシ
Lambda関数の実行が完了すると、実行環境はフリーズされ、一定期間保持されます。この間に同じ関数が再度リクエストされると、環境を再利用するため、リクエストは通常速く処理され、これを「ウォームスタート」と呼んでいます。
実稼働環境では、コールドスタートは通常、全呼び出しの1%未満で発生し、その遅延は100ミリ秒未満から1秒以上まで様々です。コールドスタートは、特に開発やテスト環境で多く見られるが、Lambdaは呼び出しパターンに基づき最適化を行い、コールドスタートの発生を最小限に抑えるようです。
※ 出展:AWSドキュメント コールドスタートとレイテンシより
Provisioned Concurrencyの基本概念
Provisioned Concurrencyの動作原理
Provisioned Concurrencyは、AWS Lambda関数がコールドスタートによる遅延を避けるために事前に実行環境をプロビジョニング(準備)しておく機能です。通常のLambda関数ではリクエストが来たときに初めて実行環境が立ち上がりますが、Provisioned Concurrencyを使用することで、指定した数の環境が常に起動して待機しているため、リクエストが発生した瞬間に即時実行できます。これにより、コールドスタートが発生することなく、安定した低遅延の応答が可能になります。
通常のConcurrencyとの違い
通常のLambda関数はリクエストが来るたびに新しい環境を立ち上げるため、初回の呼び出し時に遅延(コールドスタート)が発生する可能性があります。これに対し、Provisioned Concurrencyでは、指定された数の環境を常にアクティブな状態で待機させるため、コールドスタートの影響を受けません。通常のConcurrencyは、トラフィックに応じて動的にスケールしますが、コールドスタートが発生することがあるのに対し、Provisioned Concurrencyは一定数の環境が常に準備されているため、安定した応答が保証されます。
Lambda関数をプロビジョニングする際の仕組み
Lambda関数をProvisioned Concurrencyでプロビジョニングする際は、関数のバージョンやエイリアスに対して指定した同時実行数をプロビジョニングします。AWSはこのプロビジョニングされた数の実行環境を常に維持し、リクエストを受けたときに即座に処理が開始できる状態を保ちます。設定は、AWSマネジメントコンソールやCLIを使って行えます。
Provisioned Concurrencyの動作フロー
Provisioned Concurrencyの動作は、Lambda関数がコールドスタートを回避し、リクエストに対して即時に応答できるように、事前に実行環境をプロビジョニングすることを目的としています。これにより、Lambda関数の初回実行時やアイドル状態からの再起動による遅延を防ぎます。以下では、Provisioned Concurrencyの動作フローについて詳しく解説します。
プロビジョニングが行われるタイミング
Provisioned Concurrencyは、Lambda関数のバージョンまたはエイリアスに対して設定されます。プロビジョニングは、ユーザーがProvisioned Concurrencyを有効にし、指定した同時実行数を設定した際に初めて行われます。
AWSは指定された数の実行環境を事前に起動し、待機状態にします。
プロビジョニングされたインスタンスは常に稼働状態にあり、新しいリクエストが到着するのを待っています。
リクエスト処理時のProvisioned Concurrencyの役割
Provisioned ConcurrencyでプロビジョニングされたLambda関数は、リクエストが発生した際、すでに実行環境が立ち上がっている状態で待機しています。そのため、リクエストが到達すると同時に処理が開始され、通常のコールドスタート時に必要な初期化プロセス(インフラの起動や依存ライブラリの読み込みなど)が不要となります。
メリットとトレードオフ:Provisioned Concurrencyの効果とコストのバランス
Provisioned Concurrencyは、Lambda関数のコールドスタートを解消し、常に迅速な応答を提供できる強力な機能です。しかし、その利点を享受するためには、コストが伴います。このセクションでは、Provisioned Concurrencyの具体的なメリットと、導入に伴うトレードオフ、特にコスト面での考慮事項について詳しく解説します。
Provisioned Concurrencyのメリットとデメリット
| メリット | デメリット |
|---|---|
| 即時応答が可能 Provisioned Concurrencyにより、Lambda関数は常にウォーム状態を維持し、コールドスタートを避けることができます。これにより、リクエストが到達した瞬間に処理が開始され、特にリアルタイム処理や高頻度のAPIリクエストにおいて安定したパフォーマンスが得られます。 | コストが発生する Provisioned Concurrencyは、リクエストの有無に関わらず、指定された同時実行数のインスタンスが常に保持されるため、実行コストと保持コストが発生します。特に、利用が少ない場合やトラフィックが不規則な場合には、不要なコストがかさむ可能性があります。 |
具体的な使用シナリオ:Provisioned Concurrencyを活用すべき場面とは?
Provisioned Concurrencyは、すべてのLambdaで必ずしも必要な機能ではありませんが、特定のユースケースにおいて大きな効果を発揮します。このセクションでは、Provisioned Concurrencyを適用することで効果を最大限に発揮できる具体的なシナリオについて紹介します。
1. リアルタイムAPIの応答が求められる場合
WebアプリケーションやモバイルアプリでのAPI呼び出しは、ユーザーがインターフェース操作に対する即時のフィードバックを期待するため、コールドスタートによる遅延が致命的となる可能性があります。たとえば、チャットアプリケーションやリアルタイムデータ更新が必要なサービスでは、即座にリクエストに応答できるProvisioned Concurrencyが非常に有効です。遅延を最小限に抑えることで、ユーザー体験の向上に直結します。
2. Eコマースや決済システム
Eコマースサイトでは、特に決済処理において、遅延は顧客の離脱や売上機会の損失に直結します。プロモーション期間や、突然のトラフィック増加に対処するため、Provisioned Concurrencyを導入することで、コールドスタートによるリクエストの遅延を防ぎます。例えばブラックフライデーやサイバーマンデーのようなトラフィックが集中するイベントにおいても、安定したパフォーマンスを維持できます。
ハンズオン:AWS LambdaにProvisioned Concurrencyを適用してパフォーマンス向上を検証する
準備:Lambda関数の作成とデプロイの準備を整える
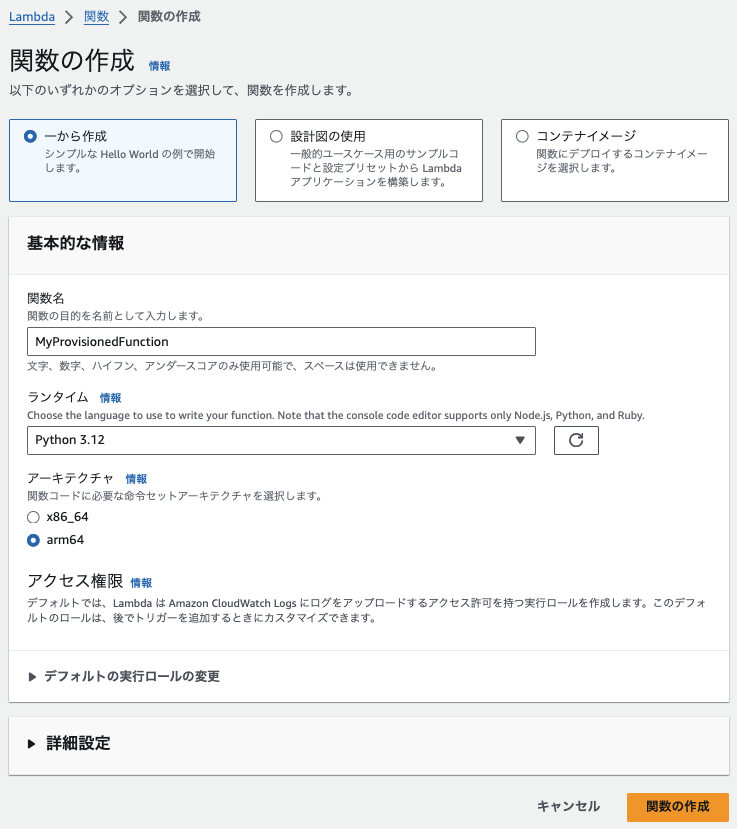
ステップ1:Lambda関数をデプロイする
- AWSにサインインし、Lambdaに移動します
- Lambdaの画面で、「関数の作成」をクリックします
- 下記を入力し、「関数の作成」をクリックします
- 関数名:任意(myPrpovisionedFunction)
- ランタイム:任意(今回はPython3.12)
4. 下記のコードを書き、「Deploy」ボタンをクリックします
ハンドラ外でかかった時刻を計測しています。
import time
import json
import logging
from datetime import datetime
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# コールドスタートの開始時刻を記録
cold_start_time = datetime.now()
logger.info(f"Cold Start - 開始時刻: {cold_start_time}")
# ダミーデータの生成
start_time = time.time()
logger.info(f"データ初期化開始時刻: {datetime.now()}")
dummy_data = [i for i in range(10000000)] # 大量のデータを初期化
end_time = time.time()
logger.info(f"データ初期化終了時刻: {datetime.now()}")
# 初期化にかかった時間をログに出力
initialization_duration = end_time - start_time
logger.info(f"データ初期化完了 - 開始時刻: {start_time}, 終了時刻: {end_time}, 経過時間: {initialization_duration}秒")
# Lambdaハンドラ
def lambda_handler(event, context):
# 初期化の時間をシミュレートするために5秒待機
time.sleep(5)
# 実行完了のログを出力
logger.info("Lambda関数の実行が完了しました")
return {
'statusCode': 200,
'body': json.dumps('Provisioned Concurrency Test with dummy data')
}
5.「設定」タブ「編集」をクリックします
6. タイムアウトを3秒から30秒に設定し、「保存」をクリックします
7. 変更されました
ステップ2:Provisioned Concurrency適用前のパフォーマンスを測定する方法
関数をテストする(一回目)
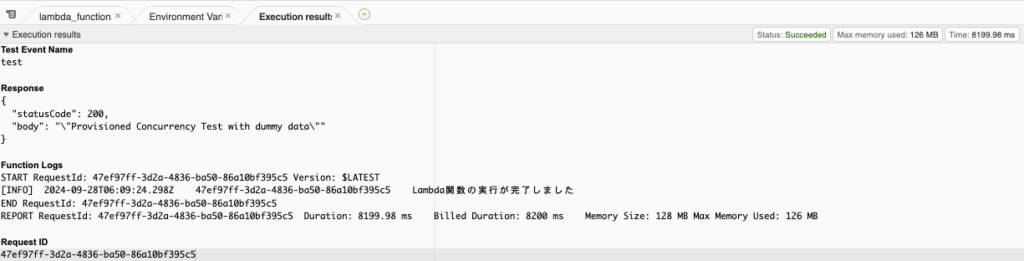
- 「Test」ボタンをクリックすると、ポップアップされるので、任意のイベント名とJSONを書いて「保存」します
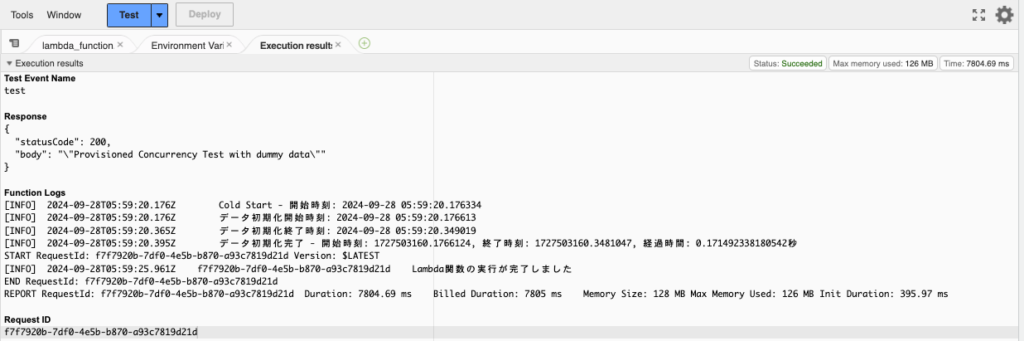
- 「Test」をクリックします。8秒程度で完了しています
- Duration: 7,804.69 ms
- Init Duration 395.97 ms
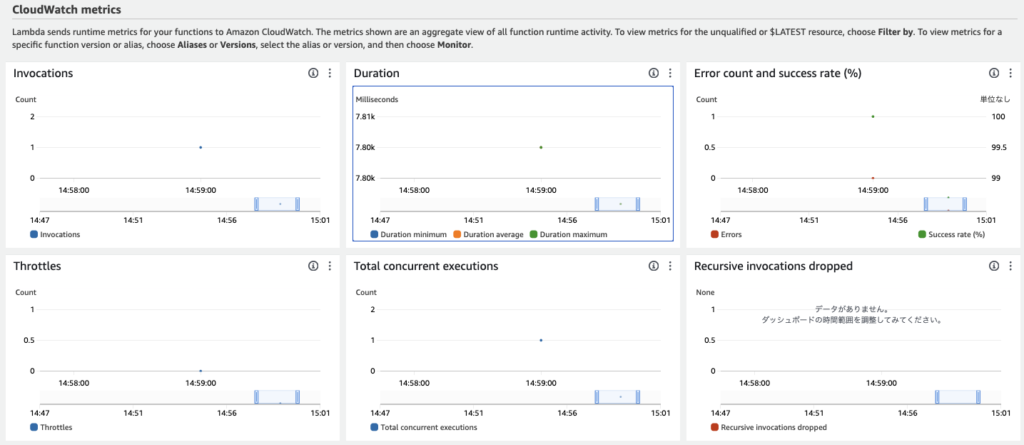
3. モニタリングタブをクリックし、メトリクスを確認します。一件実行されたこと、7.8秒(7.8K)程度かかったことがわかります。
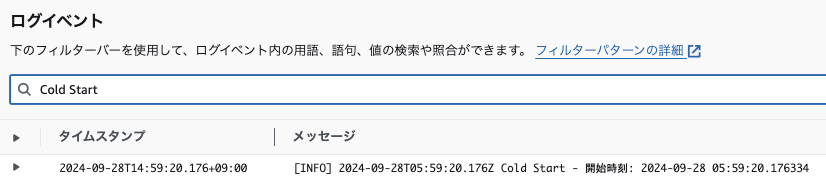
4. CloudWatch Logsでロググループを確認します。「Cold Start」で検索したところ一件引っかかりました。
関数をテストする(二回目)
今度は、ウォームアップされているはずなのでCold Startが表示されないか確認します。
1. 「Test」をクリックします
2. ログを確認すると、表示されていません。
ステップ3:AWS LambdaにProvisioned Concurrencyを設定する方法
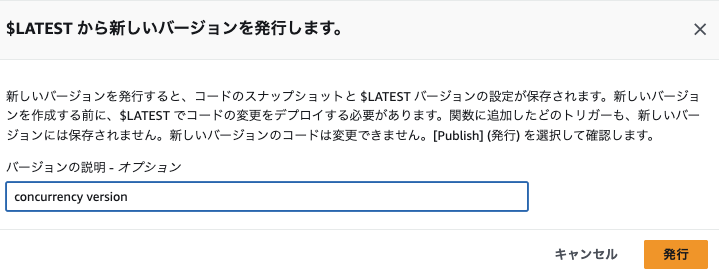
Provisioned Concurrencyは、Lambda関数のバージョンやエイリアスに対して設定されます。まず、対象のLambda関数に対してバージョンを発行する必要があります。
1.関数で、「アクション>空いたらしいバージョンを発行」をクリックします
2.バージョンを発行します
3. エイリアスを作成します
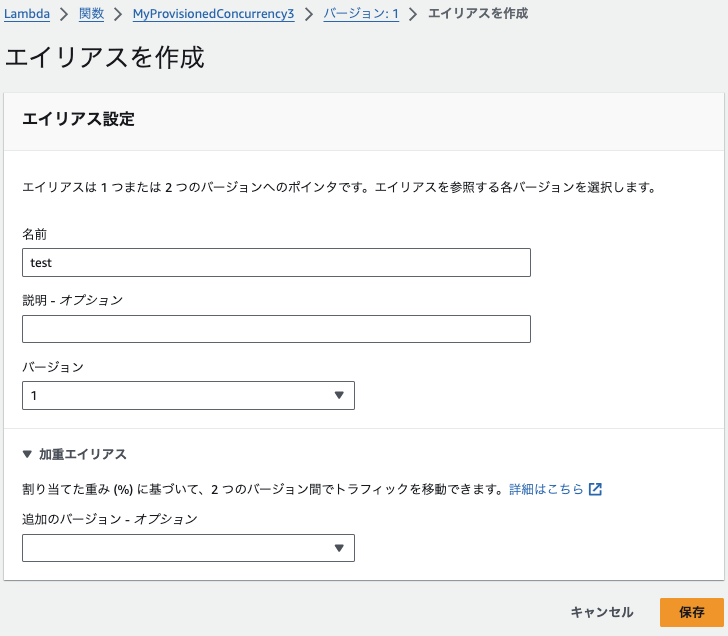
4. 名前をつけて、「保存」をクリックします
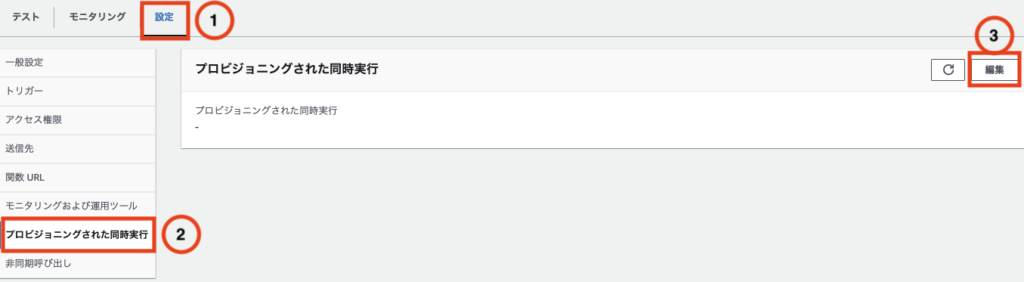
5. ①「設定」、②「プロビジョニングされた同時実行」、③「編集」をクリックします
6.「1」に設定し、「保存」します
ステップ4:Provisioned Concurrency適用後のパフォーマンス測定方法
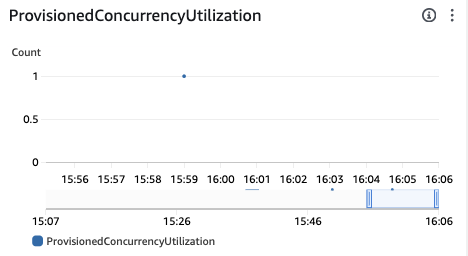
1. 「テスト」を実行します。初回はinitが発生します。

2. もう一度実行し、Lambdaの画面でProvisionedConcurrencyUtilizationが1になりました。(設定1に対して1なので100%使用されています。)
3. CloudWatch Metricsを確認します。ProvisionedConccurrencyExecutionsが呼び出されています

AWS Lambdaのパフォーマンスをモニタリングして最適化する方法
Lambdaを修正する
sleep除いた形でデプロイし、バージョンを作成しエイリアスを設定します。
import time
import json
import logging
from datetime import datetime
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# コールドスタートの開始時刻を記録
cold_start_time = datetime.now()
logger.info(f"Cold Start - 開始時刻: {cold_start_time}")
# ダミーデータの生成
start_time = time.time()
logger.info(f"データ初期化開始時刻: {datetime.now()}")
dummy_data = [i for i in range(3000000)] # 大量のデータを初期化
end_time = time.time()
logger.info(f"データ初期化終了時刻: {datetime.now()}")
# 初期化にかかった時間をログに出力
initialization_duration = end_time - start_time
logger.info(f"データ初期化完了 - 開始時刻: {start_time}, 終了時刻: {end_time}, 経過時間: {initialization_duration}秒")
# Lambdaハンドラ
def lambda_handler(event, context):
# # 初期化の時間をシミュレートするために5秒待機
# time.sleep(5)
# 実行完了のログを出力
logger.info("Lambda関数の実行が完了しました")
return {
'statusCode': 200,
'body': json.dumps('Provisioned Concurrency Test with dummy data')
}
1. CLIで10個のリクエストを5分おき程度で何回か実行します。
% for i in `seq 1 10` ;do echo $i ; aws lambda invoke --function-name MyProvisionedConcurrency3 --payload '{}' response.json --profile ${PROFILE} & ; done2. 実行を確認します
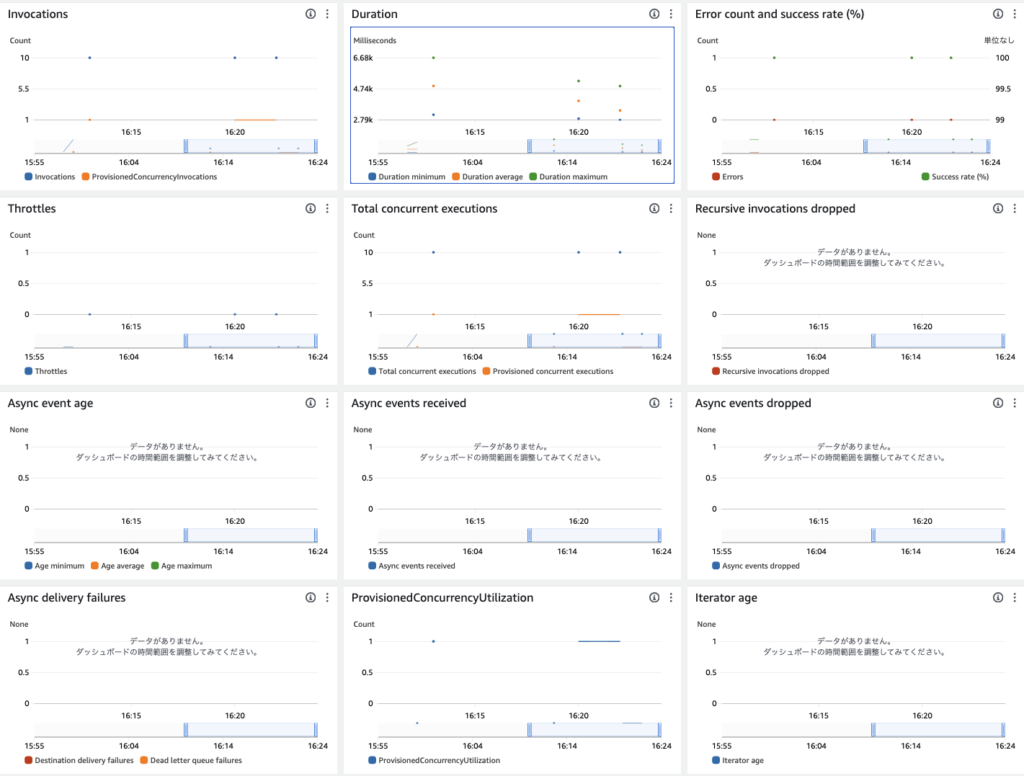
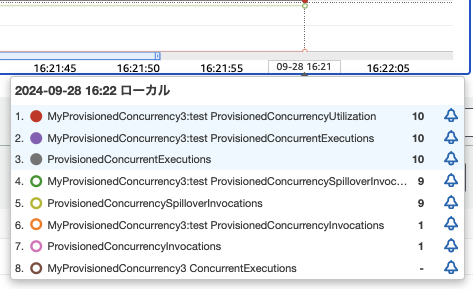
3. CloudWatch Metricsを確認します。下記のとおり、プロビジョニングされた関数は1、対応できてない関数が9にっていることがわかります。
- ProvisionedConcurrencyInvocations:1
- プロビジョニングされた同時実行を使用して関数コードが呼び出された回数
- ProvisionedConcurrencySpilloverInvocations:9
- プロビジョニングされたすべての同時実行が使用されているときに、標準同時実行を使用して関数コードが呼び出された回数
同時実行数を10に増やす
1. Lambdaに戻り、同時実行数を10に変更します
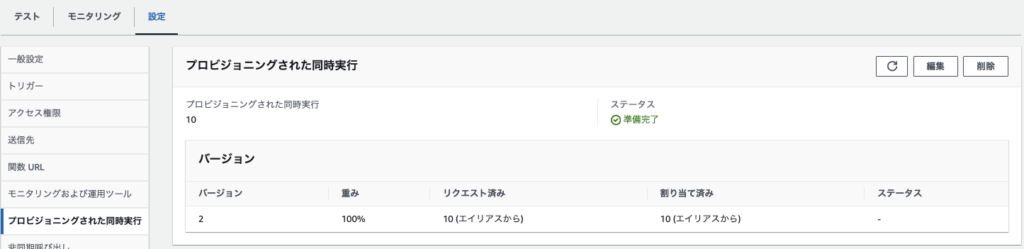
2. 再度、10並列で実行します
% for i in `seq 1 10` ;do echo $i ; aws lambda invoke --function-name MyProvisionedConcurrency3 --payload '{}' response.json --profile ${PROFILE} & ; done3. Lambdaのモニタリングを確認します。Provisioned concurrent executionsが10になりました。
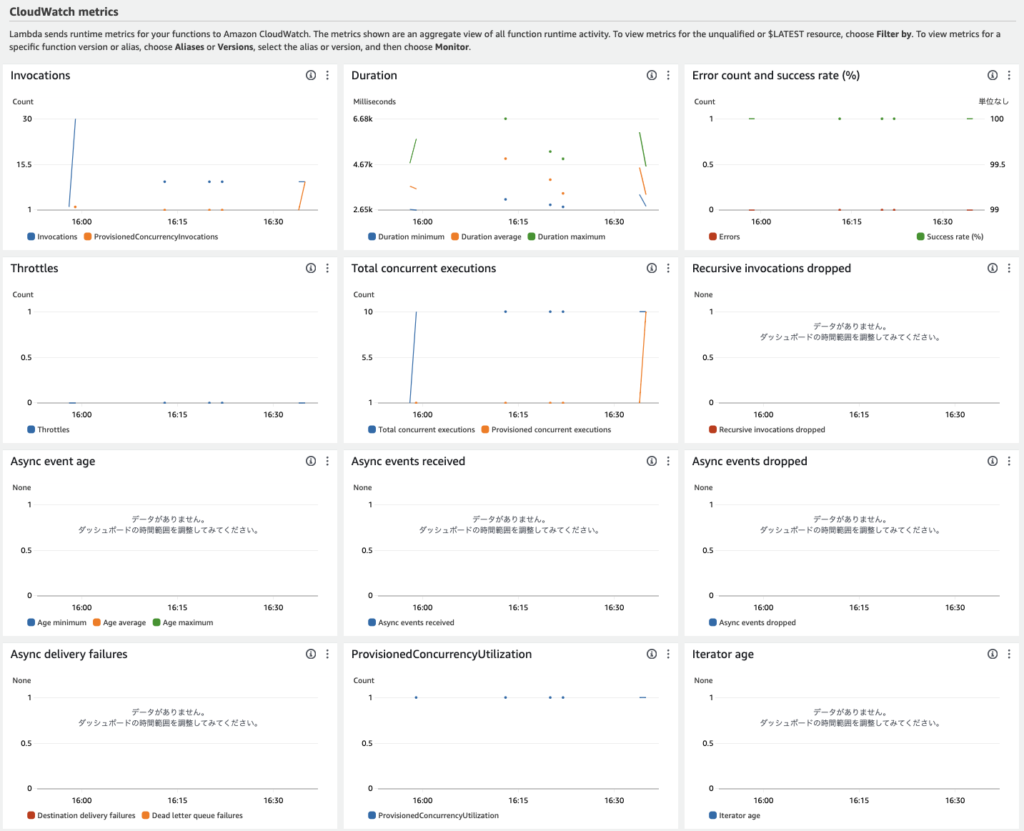
4. CloudWatch Metricsを確認します。Provisionedが聞いていることがわかります
- ProvisionedConcurrencyInvocationsが 10
- ProvisionedConcurrencySpilloverInvocationsが 0
オートスケーリングとProvisioned Concurrencyの効果的な組み合わせ方
リアルタイム性が求められるシステムやコスト効率を重視したいケースにおいて、Provisioned Concurrencyとオートスケーリングを効果的に組み合わせることが鍵となります。この記事では、この2つの機能をどのように組み合わせて、パフォーマンスとコスト効率を最大化できるかを解説します。
オートスケーリングとProvisioned Concurrencyの効果的な組み合わせ方
AWS LambdaのProvisioned Concurrencyは、関数の実行環境をあらかじめ準備することでコールドスタートを回避し、即時応答を可能にします。一方、オートスケーリングは、Lambdaの実行環境をトラフィックに応じて動的にスケールさせる機能です。これらの2つの機能を組み合わせることで、必要なときにパフォーマンスを維持しながら、不要なコストを最小限に抑えることができます。
Provisioned Concurrencyのメリットとデメリット
Provisioned Concurrencyはコールドスタートによる遅延を防ぎ、常に即時応答が求められるシステム(例えば、リアルタイムAPIや決済システム)において大きな効果を発揮します。しかし、プロビジョニングされた実行環境はリクエストがない時間帯にも保持されるため、常に一定のコストが発生します。これが、Provisioned Concurrencyの最大のデメリットです。
オートスケーリングのメリット
一方、オートスケーリングを導入することで、トラフィックの変動に応じてProvisioned Concurrency数を自動的に増減させることが可能です。これにより、トラフィックの少ない時間帯にはリソースを削減し、ピーク時に必要なリソースを迅速に確保することで、パフォーマンスとコストのバランスを保つことができます。
効果的な組み合わせ方
ピーク時のトラフィックに備える
特定の時間帯にトラフィックが集中する場合、Provisioned Concurrencyを使って予めリソースをプロビジョニングしておくことで、ピーク時の即応性を高めます。その一方で、Auto Scalingを導入して、トラフィックが少ない時間帯にはプロビジョニング数を減らすことにより、無駄なリソースの消費を防ぎます。
動的なトラフィックに対応
トラフィックの急増や急減が頻繁に発生する場合、オートスケーリングによって自動的にProvisioned Concurrency数を調整することが効果的です。CloudWatchメトリクスを活用して、リアルタイムでのトラフィックに応じたスケーリングを行うことで、過剰なコストを防ぎつつ、ユーザーに対して安定したレスポンスを提供します。
最小限のリソースを常時プロビジョニング
常に一定量のトラフィックが発生する場合は、少なくとも必要なProvisioned Concurrency数を維持し、トラフィック増加時にはAuto Scalingでスケールアウトさせる組み合わせが最適です。これにより、最小限のリソースで安定したパフォーマンスを提供できます。
応用編ハンズオン:Lambda Auto Scalingを設定して動的スケーリングを実現する
AWS Management Console(マネジメントコンソール)を使って、AWS LambdaのProvisioned Concurrencyに対してApplication Auto Scalingを設定し、トラフィックに応じて自動スケーリングを行う手順を解説します。
ステップ1:Application Auto Scalingを使用してLambdaのProvisioned Concurrencyをスケールする
1.Lambdaに移動します
2.プロビジョニングされた同時実行をクリックし、5に修正します
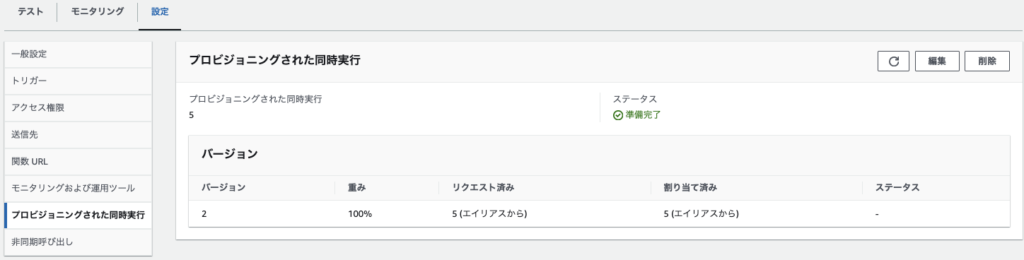
ステップ2:スケーリングポリシーの設定方法
1. CLIでApplication Auto Scalingでスケーリング可能なターゲットを登録します。このコマンドを使用して、Lambda関数のProvisioned Concurrencyをスケール対象として登録します。
% aws application-autoscaling register-scalable-target \
--service-namespace lambda \
--resource-id function:MyProvisionedConcurrency3:test \
--scalable-dimension lambda:function:ProvisionedConcurrency \
--min-capacity 1 \
--max-capacity 10 --profile ${PROFILE}
{
"ScalableTargetARN": "arn:aws:application-autoscaling:ap-northeast-1:XXXXXXX:scalable-target/XXXXXXX"
}
% 2. 設定内容を確認します。
% aws application-autoscaling describe-scalable-targets \
--service-namespace lambda \
--resource-id function:MyProvisionedConcurrency3:test \
--scalable-dimension lambda:function:ProvisionedConcurrency --profile ${PROFILE}
{
"ScalableTargets": [
{
"ServiceNamespace": "lambda",
"ResourceId": "function:MyProvisionedConcurrency3:test",
"ScalableDimension": "lambda:function:ProvisionedConcurrency",
"MinCapacity": 1,
"MaxCapacity": 10,
"RoleARN": "arn:aws:iam::XXXXX:role/aws-service-role/lambda.application-autoscaling.amazonaws.com/AWSServiceRoleForApplicationAutoScaling_LambdaConcurrency",
"CreationTime": "2024-09-28T17:05:23.214000+09:00",
"SuspendedState": {
"DynamicScalingInSuspended": false,
"DynamicScalingOutSuspended": false,
"ScheduledScalingSuspended": false
},
"ScalableTargetARN": "arn:aws:application-autoscaling:ap-northeast-1:XXXXX:scalable-target/XXXXX"
}
]
}
%
- MinCapacity:最小でプロビジョニングする同時実行数
- MaxCapacity:最大でプロビジョニングする同時実行数
- SuspendedState
- DynamicScalingInSuspended:
- スケールイン(プロビジョニング済みリソースの削減)が一時的に停止されているか
- false:通常通り / true:停止
- DynamicScalingOutSuspended:
- スケールアウト(プロビジョニング済みリソースの増加)が一時的に停止されているかどうか
- false:通常通り / true:停止
- ScheduledScalingSuspended:
- スケジュールされたスケーリング(あらかじめ設定された時間に基づくスケーリング)が停止されているかどうか
- false:通常通り / true:停止
- DynamicScalingInSuspended:
3. CloudWatchメトリクスに基づいてスケールするためのポリシーを作成します。ここでは、Lambda関数が一定のリクエスト数に達したときにプロビジョニングをスケールアウトするポリシーを設定します。
3.1. スケーリングポリシーの設定ファイルを作成します
% cat scaling-policy.json
{
"TargetValue": 0.7,
"PredefinedMetricSpecification": {
"PredefinedMetricType": "LambdaProvisionedConcurrencyUtilization"
},
"ScaleOutCooldown": 60,
"ScaleInCooldown": 120
}
% 3.2. スケーリングポリシーを作成します
% aws application-autoscaling put-scaling-policy \
--service-namespace lambda \
--scalable-dimension lambda:function:ProvisionedConcurrency \
--resource-id function:MyProvisionedConcurrency3:test \
--policy-name TargetTrackingPolicy \
--policy-type TargetTrackingScaling \
--target-tracking-scaling-policy-configuration file://scaling-policy.json \
--profile ${PROFILE}
{
"PolicyARN": "arn:aws:autoscaling:ap-northeast-1:XXXXX:scalingPolicy:XXXXX:resource/lambda/function:MyProvisionedConcurrency3:test:policyName/TargetTrackingPolicy",
"Alarms": [
{
"AlarmName": "TargetTracking-function:MyProvisionedConcurrency3:test-AlarmHigh-XXXXX",
"AlarmARN": "arn:aws:cloudwatch:ap-northeast-1:064754789454:alarm:TargetTracking-function:MyProvisionedConcurrency3:test-AlarmHigh-XXXXX"
},
{
"AlarmName": "TargetTracking-function:MyProvisionedConcurrency3:test-AlarmLow-XXXXX",
"AlarmARN": "arn:aws:cloudwatch:ap-northeast-1:064754789454:alarm:TargetTracking-function:MyProvisionedConcurrency3:test-AlarmLow-XXXXX"
}
]
}
%
4. スケーリングポリシーを確認します
% aws application-autoscaling describe-scaling-policies \
--service-namespace lambda \
--scalable-dimension lambda:function:ProvisionedConcurrency \
--resource-id function:MyProvisionedConcurrency3:test \
--profile ${PROFILE}
{
"ScalingPolicies": [
{
"PolicyARN": "arn:aws:autoscaling:ap-northeast-1:XXXXX:scalingPolicy:XXXXX:resource/lambda/function:MyProvisionedConcurrency3:test:policyName/TargetTrackingPolicy",
"PolicyName": "TargetTrackingPolicy",
"ServiceNamespace": "lambda",
"ResourceId": "function:MyProvisionedConcurrency3:test",
"ScalableDimension": "lambda:function:ProvisionedConcurrency",
"PolicyType": "TargetTrackingScaling",
"TargetTrackingScalingPolicyConfiguration": {
"TargetValue": 0.7,
"PredefinedMetricSpecification": {
"PredefinedMetricType": "LambdaProvisionedConcurrencyUtilization"
},
"ScaleOutCooldown": 60,
"ScaleInCooldown": 120
},
"Alarms": [
{
"AlarmName": "TargetTracking-function:MyProvisionedConcurrency3:test-AlarmHigh-XXXXX",
"AlarmARN": "arn:aws:cloudwatch:ap-northeast-1:XXXXX:alarm:TargetTracking-function:MyProvisionedConcurrency3:test-AlarmHigh-XXXXX"
},
{
"AlarmName": "TargetTracking-function:MyProvisionedConcurrency3:test-AlarmLow-XXXXX",
"AlarmARN": "arn:aws:cloudwatch:ap-northeast-1:XXXXX:alarm:TargetTracking-function:MyProvisionedConcurrency3:test-AlarmLow-XXXXX"
}
],
"CreationTime": "2024-09-28T20:59:22.749000+09:00"
}
]
}
%
- ScalableDimension:
- lambda:function:ProvisionedConcurrency
- スケーリングする対象の次元を示します。
- Lambda関数のProvisioned Concurrencyのスケーリングを示す次元
- lambda:function:ProvisionedConcurrency
- PolicyType:
- TargetTrackingScaling:
- スケーリングポリシーの種類
- ターゲット追跡スケーリングは、指定したメトリクスのターゲット値に応じて自動でスケーリングを行うポリシー
- TargetTrackingScaling:
- TargetTrackingScalingPolicyConfiguration
- ターゲット追跡スケーリングポリシーの設定。ポリシーの具体的な設定内容が含まれている
- TargetValue:プロビジョニング済み同時実行数の利用率の目標値
- LambdaProvisionedConcurrencyUtilizationは0.1から0.9の間で設定する
- 0.7とした場合、プロビジョニング済み同時実行数の70%を使用することを目標とすることを示します。使用率が70%を超えた場合、スケールアウト(リソース増加)します。
- PredefinedMetricSpecification:
- このスケーリングポリシーが基づくメトリクスの種類。事前定義されたメトリクスに基づいてスケーリングします。
- LambdaProvisionedConcurrencyUtilization:
- プロビジョニングされたLambdaの同時実行数の使用率に基づいてスケーリングすることを示します。
- ScaleOutCooldown:
- スケールアウト(リソース増加)後に、次のスケールアウトが行われるまでの待機時間(クールダウン期間)。単位は秒。
- スケールアウト後に、次のスケールアウトを行うまで60秒間待機する設定
- ScaleInCooldown:
- スケールイン(リソース削減)後に、次のスケールインが行われるまでの待機時間(クールダウン期間)。単位は秒。
- スケールイン後に、次のスケールインを行うまで120秒間待機する設定
- Alarms:
- このスケーリングポリシーに関連付けられたCloudWatchアラームのリストです。スケーリングのトリガーとして機能します。
- AlarmName:
- CloudWatchアラームの名前。
ステップ3:スケーリングテストの実行と結果確認
100件のリクエストを実行する
1.同時リクエスト「100」で実行します。
% for i in `seq 1 100` ;do echo $i ; aws lambda invoke --function-name MyProvisionedConcurrency3:test --payload '{}' response_$i.json --profile ${PROFILE} & ; done2.CloudWatch Metricsを確認します。
- Provision済みが14
- それ以外が86

10で実行します
1. しばらくあけて、同時リクエスト「10」で実行します。
for i in `seq 1 10` ;do echo $i ; aws lambda invoke --function-name MyProvisionedConcurrency3:test --payload '{}' response_$i.json --profile ${PROFILE} & ; done 2.現在の値を確認します
% aws lambda get-provisioned-concurrency-config \
--function-name MyProvisionedConcurrency3:test \
--qualifier test --profile ${PROFILE}
{
"RequestedProvisionedConcurrentExecutions": 10,
"AvailableProvisionedConcurrentExecutions": 10,
"AllocatedProvisionedConcurrentExecutions": 10,
"Status": "READY",
"LastModified": "2024-09-28T08:53:00+0000"
}
% - RequestedProvisionedConcurrentExecutions:
- リクエストされたプロビジョニング済み同時実行数
- AvailableProvisionedConcurrentExecutions:
- 現在使用可能なプロビジョニング済み同時実行数
- AllocatedProvisionedConcurrentExecutions:
- 割り当てられたプロビジョニング済み同時実行数
3. しばらくすると、スケールインしていく様子がわかります。
% aws lambda get-provisioned-concurrency-config \
--function-name MyProvisionedConcurrency3:test \
--qualifier test --profile ${PROFILE}
{
"RequestedProvisionedConcurrentExecutions": 9,
"AvailableProvisionedConcurrentExecutions": 9,
"AllocatedProvisionedConcurrentExecutions": 9,
"Status": "READY",
"LastModified": "2024-09-28T09:23:23+0000"
}
% aws lambda get-provisioned-concurrency-config \
--function-name MyProvisionedConcurrency3:test \
--qualifier test --profile ${PROFILE}
{
"RequestedProvisionedConcurrentExecutions": 8,
"AvailableProvisionedConcurrentExecutions": 9,
"AllocatedProvisionedConcurrentExecutions": 9,
"Status": "IN_PROGRESS",
"LastModified": "2024-09-28T09:26:23+0000"
}
% aws lambda get-provisioned-concurrency-config \
--function-name MyProvisionedConcurrency3:test \
--qualifier test --profile ${PROFILE}
{
"RequestedProvisionedConcurrentExecutions": 8,
"AvailableProvisionedConcurrentExecutions": 8,
"AllocatedProvisionedConcurrentExecutions": 8,
"Status": "READY",
"LastModified": "2024-09-28T09:26:23+0000"
}
%
4. さらに確認します。min-capacityの1まで減りました。
% aws lambda get-provisioned-concurrency-config \
--function-name MyProvisionedConcurrency3:test \
--qualifier test --profile ${PROFILE}
{
"RequestedProvisionedConcurrentExecutions": 1,
"AvailableProvisionedConcurrentExecutions": 1,
"AllocatedProvisionedConcurrentExecutions": 1,
"Status": "READY",
"LastModified": "2024-09-28T13:10:01+0000"
}
%
FAQ:AWS LambdaのProvisioned Concurrencyに関するよくある質問
1. どのくらいのProvisioned Concurrencyを設定すべきですか?
A. Provisioned Concurrencyの設定数は、アプリケーションのトラフィックパターンによって異なります。基本的な考え方は、ピークトラフィックの期間中に処理する必要があるリクエスト数に基づいて設定することです。具体的には、平均リクエスト数 × 予想されるピーク期間の持続時間で計算できます。たとえば、1分間に100リクエストが来る場合、Provisioned Concurrencyを「100」に設定すると、コールドスタートなしで全リクエストに対応できるようになります。
2. Provisioned Concurrencyを設定すると、コストはどう変わりますか?
A. Provisioned Concurrencyを設定すると、通常のLambdaの実行コストに加えて、プロビジョニングされたインスタンスの維持コストが追加されます。Provisioned Concurrencyの料金は、プロビジョニングされた同時実行数 × 稼働時間で計算され、これはLambda関数がアクティブでないときでも課金されます。したがって、トラフィックのパターンが予測可能で、一定量のトラフィックがある場合にコスト効率が良くなる傾向があります。トラフィックの変動が激しい場合は、通常のスケーリングメカニズムを使用する方がコスト効率が良い場合もあります。
3. Provisioned Concurrencyは全てのLambda関数で有効ですか?
A. いいえ、Provisioned Concurrencyは特定のバージョンまたはエイリアスに対して設定されます。つまり、関数の特定バージョンに対してのみProvisioned Concurrencyを有効にでき、すべてのバージョンや最新のデプロイされた関数には自動的に適用されません。バージョン管理を行い、特定のバージョンに適用することで安定したパフォーマンスが得られます。
4. トラフィックが予測できない場合でもProvisioned Concurrencyを使用すべきですか?
A. トラフィックが予測不可能な場合は、Auto Scalingなどの動的なスケーリング機能と組み合わせて使用することを検討してください。Provisioned Concurrencyは、特定のトラフィックピークが予測可能な場合に特に効果を発揮します。例えば、毎朝のバッチ処理や定期的なピーク時間があるサービスに対して適用するのが効果的です。
参考資料とリソース:Provisioned Concurrencyのさらなる学習のために
リソース




まとめと今後の活用方法:Provisioned Concurrencyを効果的に運用するために
まとめ:AWS Lambda Provisioned Concurrencyの要点を振り返る
AWS LambdaのProvisioned Concurrencyは、コールドスタートを防ぎ、常に即時にリクエストを処理できる実行環境を事前にプロビジョニングしておく仕組みです。これにより、リアルタイム処理が重要なシステムや高頻度アクセスを処理するアプリケーションにおいて、安定したパフォーマンスを提供できます。
要点の振り返り:
- コールドスタートの回避: Provisioned Concurrencyは、Lambda関数の実行環境を事前にウォーム状態で準備しておくため、リクエスト時の初回遅延(コールドスタート)を防ぎます。これにより、リクエストに即座に応答でき、ユーザー体験を向上させます。
- プロビジョニング数の管理: ユーザーは、必要なプロビジョニング済みの同時実行数を設定できます。また、スケーリングポリシーを適用することで、リクエストの増減に応じてプロビジョニング済みの実行環境が自動的に増減します。
- スケールアウトとスケールイン:
- スケールアウトは、プロビジョニングされた同時実行数の使用率が設定されたターゲット(例:70%)を超えた際に発動し、追加のリソースをプロビジョニングします。
- スケールインは、リクエストが減少した場合にリソースを削減し、コスト効率を最適化します。ただし、スケールインのタイミングやリソース削減は段階的に行われる場合があります。
- クールダウン期間の設定: スケールインやスケールアウトの後には、クールダウン期間が設定されており、この期間中は追加のスケール操作が行われません。これにより、短時間での頻繁なリソース変更を防ぎ、システムの安定性を保ちます。
- コスト管理: Provisioned Concurrencyは、リクエストが少ない場合でもプロビジョニングされた実行環境に対してコストが発生します。そのため、リクエストの予測やスケーリングポリシーの最適化がコスト管理の重要なポイントです。
次のステップ:プロジェクトにProvisioned Concurrencyを適用するための最初のステップ
Provisioned Concurrencyを実際にプロジェクトに導入する際、まずは小規模なテストから始めます。以下のステップに従って、導入の最初の段階をスムーズに進めます。
1. トラフィックパターンを分析する
最初に、アプリケーションやサービスのトラフィックパターンを分析します。特定の時間帯にトラフィックが急増するか、一定量のリクエストが定期的に発生するかを確認します。これにより、Provisioned Concurrencyが適用できる最適な関数を見つけることができます。
2. 適用対象のLambda関数を選定する
トラフィック分析を基にProvisioned Concurrencyを導入すべきLambda関数を選定します。例えば、APIのエンドポイントや、バッチ処理など、コールドスタートによる遅延が問題となりうる関数を優先的に選びます。
3. 小規模なスケールで試験導入を行う
プロジェクトの全ての関数に適用するのではなく、まずは1つの関数に対して少数のProvisioned Concurrencyを設定し、パフォーマンスとコストへの影響を測定します。これにより、リスクを最小限に抑えたテスト環境を作ります。
4. CloudWatchでパフォーマンスをモニタリングする
導入後は、CloudWatchで「ProvisionedConcurrencyInvocations」や「Duration」などのメトリクスを監視し、Provisioned Concurrencyの効果を確認します。これにより、リクエストの遅延が減少しているか、適切なプロビジョニング数が設定されているかが判断します。
5. フィードバックを基に調整する
小規模な導入の結果をもとに、Provisioned Concurrency数の調整や、他のLambda関数への適用範囲の拡大を検討します。また、必要に応じてAuto Scalingなどの追加機能も活用して、動的にプロビジョニングを調整することも考慮します。


コメント