
データメッシュは比較的新しい概念や手法です。これは、企業や個人がデータを効率的に管理、活用するためのアプローチです。この記事では、データメッシュの基本的な概念から特徴、そして用途まで幅広く解説します。さらに、他のデータ管理手法との比較や、導入に必要な技術についても詳しく説明します。本記事は、初心者から経験者までを対象とし、データメッシュについての理解を深めることを狙いとしています。特に、複数の事業や部門がある大企業や、多くのステークホルダー、プロダクトを保有している企業に対して参考になります。
- 初心者から経験者まで: データメッシュについて基本的な知識から応用までを学びたい人。
- データ基盤のアーキテクトまたはデータ基盤の責任者: 大企業でデータ基盤の設計や運用に携わっている人。複数の事業や部門、多くのステークホルダー、プロダクトに関わるデータを管理しており、新しいデータ管理手法に興味があり、その導入を検討している。
- 基本概念の理解: データメッシュの基本的な概念と特徴を把握し、現場でのデータ管理と活用にどう活かせるかを理解できる。
- 効率的なデータ活用: データメッシュを用いたデータ管理と活用の具体的な手法を学び、業務効率を向上させる。
- 他手法との比較知識: データメッシュと他のデータ管理手法(例:データレイク、データウェアハウス)との比較を理解し、どの手法が現場で最も適しているかを判断できる。
- 導入計画の策定: データメッシュ導入に必要な技術やツールについての知識を得て、導入計画を具体的に考えられるようになる。
- ステークホルダーとのコミュニケーション: データメッシュの利点や必要性を明確に説明できるようになり、ステークホルダーとのコミュニケーションがスムーズになる。
データメッシュ入門:基本概念とその重要性を解説
本章では、データメッシュとは何か、その基本的な概念となぜ今、注目されているのかを明らかにします。
データメッシュとは?
データメッシュは、データの管理と活用を効率的に行うための新しいアーキテクチャの手法です。従来の集中型のデータ管理手法(例:データレイク、データウェアハウス)とは異なり、データメッシュは分散型のアプローチを採用しています。この手法は、データを各部門やチームが独立して管理・活用することを可能にし、組織全体でのデータの利用効率を高めます。
なぜ注目を集めるのか?
今、データメッシュが注目されているのかというと、データの量が急速に増加している現代において、従来の集中型のデータ管理手法がスケーラビリティと効率性で限界に達しているからです。データメッシュは、この問題を解決するための有望な手法とされています。
従来のデータ管理手法とは、データレイクとその基盤を管理する中央型組織が当てはまります。
私は集中型と分散型であるデータメッシュには、それぞれで下記の特徴があると考えます。
アーキテクチャの比較 (集中管理 vs 分散管理)
対比する形で記載しましたが、集中型と分散型のどちらが優れているのか?というわけではないと考えます。現在の組織で何を求めるか?だと考えます。
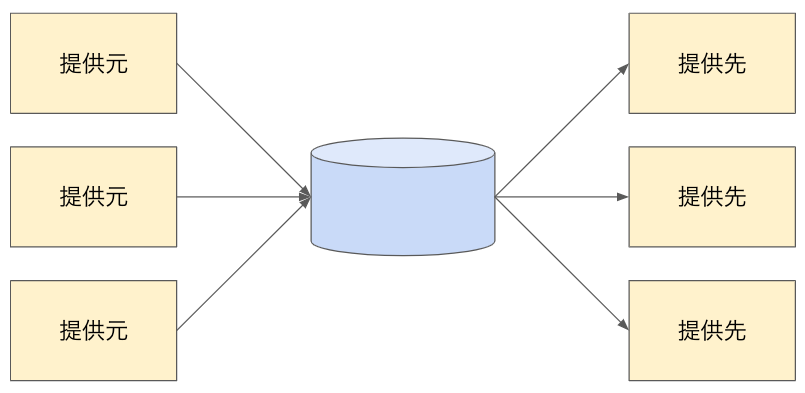
集中型(データレイク)
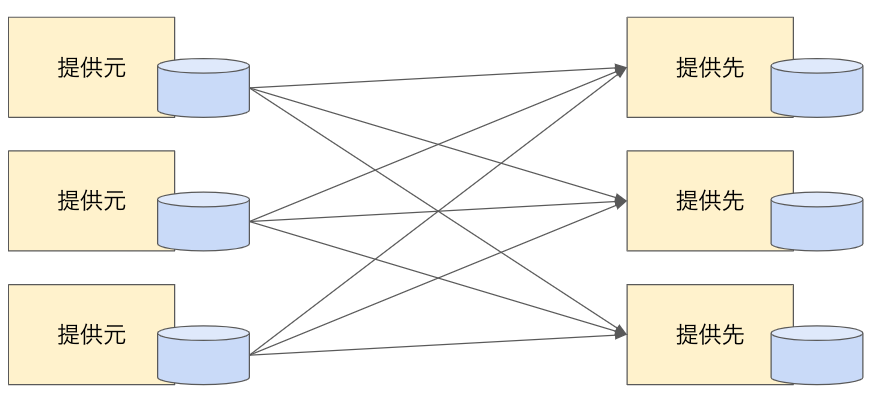
分散型(データメッシュ)
| 特徴 | 集中型(データレイク) | 分散型(データメッシュ) |
|---|---|---|
| 概要 | データソース、データレイク、データ提供先と管理主体、およびアーキテクチャが異なるのが一般的 | 中央組織による管理主体は無い。データソースとデータ提供先で直接接続し連携する |
| データの所有権(管理主体) | 中央組織のチームがデータを管理する | データソースを保持しているチーム、データ提供先のチームが管理主体となる。 |
| スケーラビリティ | 中央組織の対応力そのものがスケールの上限になる | データソース、データ提供先のチームの対応する余力がある限りスケール可能 |
| 柔軟性と拡張性 | 上記の通り中央組織に依存するため、柔軟性と拡張性は皮下kすると無い | データソース、データ提供先のチームの余力次第で、ボトルネックが生まれづらい構造のため、中央型と比較して、柔軟であり拡張性がある |
| データアクセスの複雑さ | データは一箇所に集まるためアクセスのパターンは限られるためシンプル | データは複数に配置されるためアクセスは多発的に多岐にわたり行われるため、複雑 |
| ガバナンスとセキュリティ | データは一箇所に集まるため統一して管理しやすい。 | データは複数に配置されるため、一律の管理は難しい。 |
| データ統合と品質 | データは中央組織で一括して統合管理する。また品質も合わせて行うので管理しやすい | データは各チームで保持するため、統合や品質管理もも各チームで行うため、管理しづらい |
データメッシュの独自性:主要特徴とビジネスへのインパクト
データメッシュのユニークな特徴と、それが大企業や多部門・多ステークホルダー企業にどのように貢献するのかを詳細に解説します。データメッシュの一つのユニークな特徴は、各部門やチームが独立してデータを管理・活用することができる点です。これにより、データの利用効率が組織全体で高まります。
例えば、マーケティング部門は顧客データを、製造部門は製品データをそれぞれ独立して管理・分析できます。これにより、各部門が必要なデータに迅速にアクセスし、より効率的な意思決定が可能になります。
また、データメッシュはスケーラビリティに優れています。従来の集中型のデータ管理手法では、データの量が増えるとその管理が複雑になり、結果的に効率が落ちてしまうことが多いです。しかし、データメッシュではこのような問題が発生しにくく、大企業や多部門・多ステークホルダー企業にとって非常に有用です。
以上のように、基本概念と独自性で取り上げるポイントは異なり、それぞれが独自の価値とインパクトを持っています。
集中型(データレイク)と分散型(データメッシュ)のどちらを選ぶか?
データ基盤のアーキテクトの経験有無と、データ取得元と連携先のステークホルダーの多さ(この場合、チーム数)で判断すると良いと思います。
分散型アーキテクチャと集中型アーキテクチャは全く別物か?
まずはじめに、どちらを選択するか?の前に、集中型アーキテクチャと分散型アーキテクチャが異なる点を論理アーキテクチャを用いて整理します。
下図はデータレイクアーキテクチャで、ストレージ層を複数のレイヤー(Raw/Storing/Deliver)に分けて、収集、蓄積、加工のETLを実施している様子です。※このETLは各社の状況により変わります。

下図にデータメッシュアーキテクチャを記載します。上記と比較してStoringまでデータ提供元で蓄積・加工します。※このETLは各社の状況により変わります。
Storingのデータは、データ連携先に対して公開し、利用してもらいます。このようにデータレイクとデータメッシュでは境界が異なる点と、複数のステークホルダーで構成されるかの違いであることがわかります。
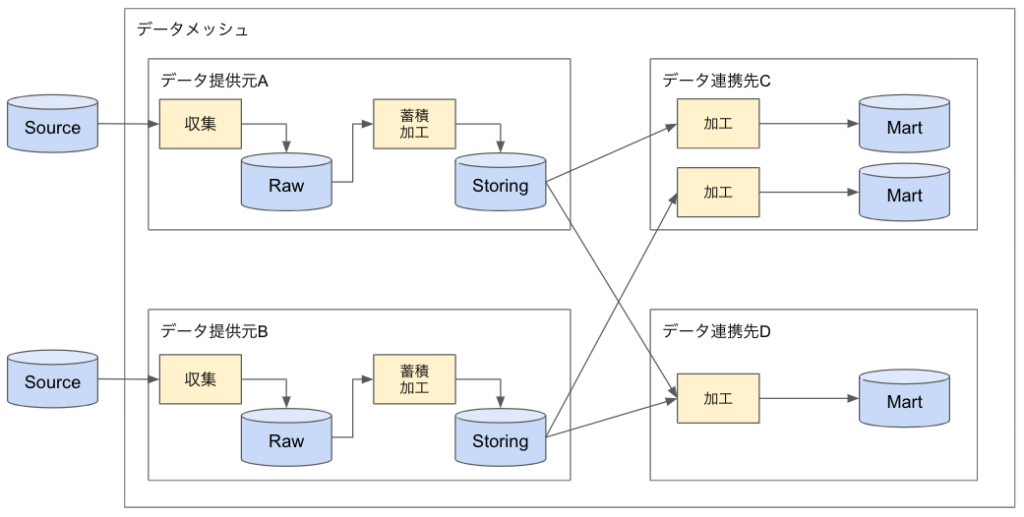
どちらを選択すべきか?
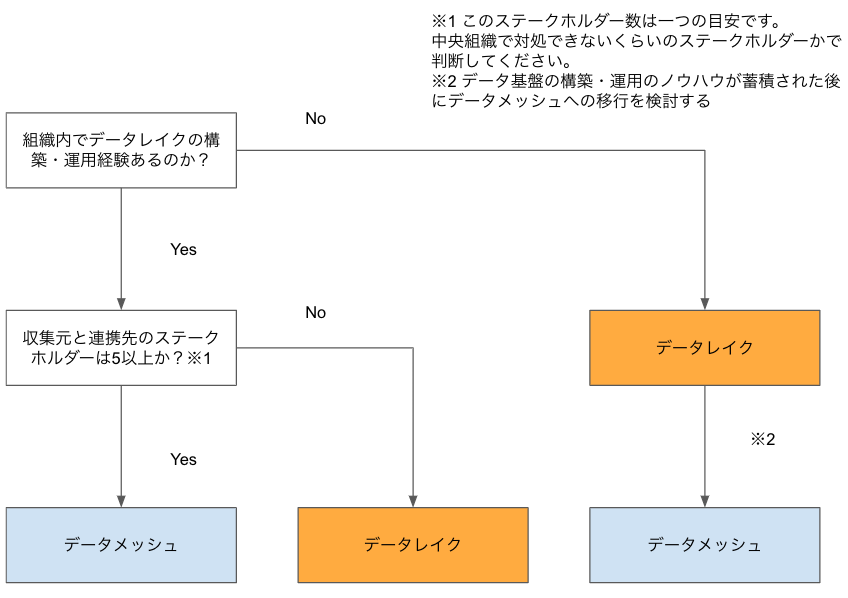
上記の通り、分散型アーキテクチャ(データメッシュ)は、集中型(データレイク)が拡張されたものと読み取れます。そのため、組織に集中型のアーキテクチャのノウハウを持っているかが一つの基準になります。
一つの考え方として、組織の成熟度とステークホルダーの数で判断します。下記に判断のフローチャートを載せます。
データメッシュの4つの原則: データオーナーシップから連合型ガバナンスまで
データメッシュ成功のための4つの原則(データオーナーシップ、プロダクトとしてのデータ、セルフサービス型のデータ基盤、連合型データガバナンス組織)があります。
これらの原則を理解、実践することでデータメッシュの導入をスムーズに進められます。
データメッシュ原則の1: データオーナーシップ
各プロダクトで保持するデータに対して、担当するチームは責任やオーナーシップを持ちます。
データメッシュ原則の2: プロダクトとしてのデータ
自らのデータに対して、他のチームから参照されるため品質を保証し、利用促進のためメタデータを充実させる必要があります。
データメッシュ原則の3: セルフサービス型のデータ基盤
各チームでETLや分析を行うために、自身で利用できるために必要なデータ基盤を提供します。
データメッシュ原則の4: 連合型データガバナンス
専門的なロールで構成される連合型組織で、データガバナンスを担保します。
データメッシュ導入ガイド:必須技術とベストプラクティス
データメッシュを導入する際に必要な技術要件と、成功するためのベストプラクティスを提供します。
品質管理とメタデータ管理
データメッシュ原則1「データオーナーシップ」と原則2「プロダクトとしてのデータ」を実現するため、高品質で汎用的なデータセットを提供する必要があります。そのため、下記のような管理機能を導入する必要があります。
- 品質管理
- データリネージ
- メタデータ管理
セルフサービス型のデータアーキテクチャ
各チーム自身で、加工・編集、分析などを行うため必要なETLやBIツールなどを提供します。下記のような機能の導入を検討します。また運用コストを削減するためサーバレスなプロダクトの導入を検討すると良いでしょう。
- ETL
- BIツール
- Notebook
データガバナンス
各チーム間でデータ連携する際に、データ共有の要求と合意を行ったうえでアクセスします。そのため下記の機能の導入を検討します。
- 要求・合意の記録
- データアクセス管理
- アクセス記録と監査
よくある質問
データメッシュとは何ですか?
データメッシュは、大規模な組織に適している分散データアーキテクチャの一つで、データを効率的に管理し、アクセスするためのアプローチです。
詳細は、こちらをご確認ください。
データメッシュの主な特徴は何ですか?
データメッシュの主な特徴には、4つの原則が挙げられます。データオーナーシップ、プロダクトとしてのデータ、セルフサービス型のデータ基盤、連合型データガバナンスなどが含まれます。
詳細は、こちらをご確認ください。
データメッシュには、どのようなメリットがありますか?
大規模な組織、多くのステークホルダーがいる組織にとってデータ利活用を行う際に、スケールや拡張性、迅速さなどのメリットがあります。
データメッシュの具体的な技術要素は何ですか?
データメッシュには、データレイク、データカタログ、データパイプライン、データセキュリティなどの技術要素が含まれます。
データメッシュをAWSで実装するには?
下記の記事が参考になるかと思います。

データメッシュをAzureで実装するには?
下記の記事が参考になるかと思います。

データメッシュをSnowflakeで実装するには?
下記の記事が参考になるかと思います。

データレイクとデータメッシュの違いを教えてください。
それぞれの特徴と違いは、アーキテクチャの比較 (集中管理 vs 分散管理)を参照してください。
データメッシュとデータファブリックの違いを教えてください。
データメッシュは、組織内のデータサイロを解消し、データの所有と責任を明確にすることに焦点を当てています。一方で、データファブリックは、異なるデータソースとテクノロジーを一元的に統合し、効率的なデータアクセスと利用を可能にすることを目的としています。
データファブリックは、異なるデータソースやストレージ、アプリケーション間でデータを効率的に管理、アクセス、活用するための統合されたアーキテクチャです。主な特徴としては、以下の点があります。
- 統合されたデータアクセス: 異なるデータソースとストレージにまたがるデータの統合アクセスを提供。
- セマンティックレイヤー: データの意味や文脈を理解するためのレイヤーを持つ。
- 集中ガバナンス: データの品質、セキュリティ、プライバシーが一元管理される。
- テクノロジー中立: 既存のテクノロジーと統合することができるように設計。
- リアルタイム処理: リアルタイムでのデータ処理と分析が可能。
特に大規模なデータ環境や複数のデータソースを持つ組織で有用です。データファブリックは、データの一元管理と効率的な活用を目的としています。
データメッシュを導入する際のベストプラクティスは何ですか?
データメッシュの導入においては、組織全体のコラボレーション、データガバナンスの確立、適切なツールの選定などが重要なベストプラクティスです。
最後に
データメッシュについての事例や導入のステップなどは、あまり公開されていません。今回の記事が皆様のヒントになれば幸いです。今後もデータメッシュの記事を公開していきます。


コメント