
この記事は、DMBOK2のデータマネジメントの「データ統合と相互運用性」について、概要を解説します。
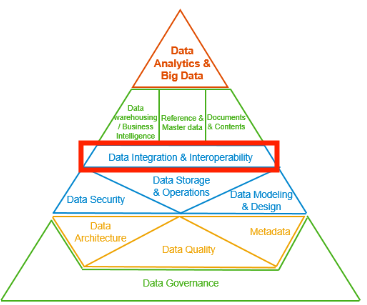
この「データ統合と相互運用性」は、DMBOK2の知識エリアの一つであり、Peter AikenのFrameworkでは、Reference & Master dataやData warehousing / Business Intelligence等の直下、全体から見て下から3番目のレイヤ(下図の赤枠参照)に位置します。
特徴としては、同じ層や下層の2つの設計や運用に支えられます。特に下記のレイヤのデータ管理機能が必要になります。(参照データとマスタデータだけで十分と考えないことを留意してください。)
- 1層(一番下):Data Governance
- 2層:Data Architecture、Metadata
- 3層:Data Security、Data Storage & Operations、Data Modeling & Design
本記事の想定読者と、読むことで得られる内容は下記のとおりです。
- データマネジメント、特に「データ統合と相互運用性」を体系的に学びたい方
- データ統合と相互運用性とは何か?また、何故必要か?
- プロジェクトの進め方や論点がわかる。
データ統合と相互運用性とは?
データの移動と統合に関するプロセスを指し、物理仮想を問わない一貫したソリューションを提供します。
データ統合と相互運用性は、下記の相互間で実行されるデータの移動と統合に関するプロセスを表しています。
- データストア
- アプリケーション
- 組織等
データ統合は、データを物理的、仮想的問わずに一貫したソリューションを提供します。
データ統合と相互運用性のソリューションでは、下記のような基本的なデータマネジメント機能をカバーしています。
- データの移行と変換
- ハブやマートへの変換
- 組織が持つアプリケーションポートフォリオへのベンダーパッケージの組み込み
- アプリケーションと組織を横断したデータ共有
- データストアとデータセンター間でのデータ通信
- データのアーカイブ
- データインタフェイスの管理
- 外部データの入手と取り込み
- 構造化データと非構造化データの統合
- オペレーショナルインテリジェンスと経営意思決定支援の提供
なぜ、データ統合と相互運用性が必要か?
下記の効果を期待する。
- データ移動の効率的な管理
- サポートと人件費の削減
- トラブルシューティング作業の効率化
- コンプライアンスの検証を簡素化
組織内の数百、数千のデータを移動するプロセスがあり、それによりITリソースが逼迫する可能性があります。そのためデータの移動を効率的に管理することが重要です。
このデータ移動では、アプリケーション間のエンドツーエンド型のソリューションではインタフェイスが膨大に増えてしまうため、下記のようなソリューションによりインターフェイスをシンプルにすることで管理を減らします。
- データウェアハウス(DWH)やマスタデータ管理のソリューションなどのデータハブソリューション
- ハブ&スポーク型の統合、カノニカル・メッセージモデル等のデータ統合技法
また、複数の統合技術を利用することで、それぞれの技術ごとに開発と保守のスキルが必要になりサポートコストも掛かります。標準的なツールを導入することでサポートと人件費を削減し、トラブルシューティング作業を効率化します。
上記により、組織はデータ取り扱い標準と規則を遵守できるようになり、コンプライアンス規則に準拠するプログラムが再利用でき、コンプライアンスの検証を簡素化出来ます。
データ統合と相互運用性の目指す姿(ゴール)
データ統合と相互運用性のゴールには、下記のとおりです。
- 人とシステムそれぞれが必要とするフォーマットとタイムウィンドウでデータを提供出来るようにする
- データを物理的および仮想的にデータハブに集約する
- モデルとインタフェイスを開発し共有することでソリューションを管理するコストと複雑さを削減する
- 重要なイベント(機会と脅威)を特定し、自動的にアラートとアクションをトリガーする
- ビジネスインテリジェンス、アナリティクス、マスタデータ管理、業務効率化の取り組みをサポートする
データ統合と相互運用性の原則
データ統合と相互運用性は、下記の原則に従わなければなりません。
- 設計上は将来的に拡張性を確保するために全社視点が必要だが、実装は反復的かつ段階的に行う。
- 担当部署のデータニーズと全社的なデータニーズのバランスをとる。サポートと保守の視点も含む
- データ統合と相互運用性の設計と活動のための業務上の責任を確実に全うする。業務の専門家は永続的データと仮想的データ双方の変換ルールを設計したり変更したりする際に関与する必要がある。
データ統合と相互運用性の概念
ETL(Extract、Transform、Load)
データ統合と相互運用性に関わる全領域の中心に、ETLという基本プロセスがあります。
ETLは、Extract(抽出)、Transform(変換)、Load(ロード)の略です。データ移動する際のプロセスを表したものです。
データストアから、データを「抽出」し、目的に応じた「変換」をかけて、別のデータストアで参照できるように「取り込み(ロード)」します。
ETLは、下記のタイミングで実行されます。通常オペレーショナルデータはリアルタイムまたは、ニアリアルタイムで行われますが、分析やレポーティングなどに組み込まれることが多いです。
- 定期的なスケジュール(◯時に稼働など)
- イベント駆動(ファイル作成をトリガーに稼働など)やリアルタイム(データが流れてきたら随時)
ETLと似ていますが、ELTというプロセスもあります。
これは、それぞれの頭文字を取っているのは同じですがETLと順番が違います。
データストアから、データを「抽出」し、別のデータストアに「取り込み(ロード)」した後で、目的に応じた「変換」をかけます。
次に、ETLそれぞれの要素について解説します。
Extract(抽出)
データソースから抽出します。抽出したデータはディスク上の物理的なストレージやメモリにステージングします。(一時保存されます。)
オペレーショナルデータソースに影響を与えないように、下記のような工夫が必要です。
- 差分データだけ(フルスキャンしない)
- Pullではなく、Pushするメカニズム(データベースの変更後ログを使用する)
- レプリケーションされた読み取りデータストアを利用
Transform(変換)
下記のような変換をかけることで、ターゲットデータストアと同様のフォーマットにする。変換後のデータはステージングされたストレージ等に格納する。
| 変換 | 処理内容 |
|---|---|
| フォーマット変更 | CSVからParquetなど |
| 構造変更 | 非正規化レコードから、正規化レコードへ |
| 意味的変換 | 一貫性のある意味的表現に変更。 0,1を、UNKNOWN、UPDATEDのように |
| 重複排除 | 左記のとおり |
| 並べ替え | 左記のとおり |
Load(ロード)
変換結果をターゲットシステムに物理的に格納するか、提供されます。
ターゲットのデータは、用途により最終形であったり、さらに変換をかけたりする場合があります。
レイテンシ またはターンアラウンドタイム(TAT)
DMBOK2では、レイテンシ(遅延)という表現で、ETLの処理時間を説明しています。
筆者の私の経験上、レイテンシは画面の応答速度などミリ秒〜秒単位の世界を表現する用語で利用してきました。
情報処理試験等で登場する、人がジョブを投入してから結果が返るまでのターンアラウンドタイムを好んで利用しています。
そのため、ETLにかかる時間は、本記事ではターンアラウンドタイム(TAT)と表現したいと思います。
ターンアラウンドタイム(以降、TATと言います。)は、ソースシステムからデータを抽出してからターゲットシステムにロードするまでの時間の差分です。
データ処理のアプローチによりTATの度合いが異なります。
| アプローチ | レイテンシまたはTAT | 概要 |
|---|---|---|
| バッチ | 長い | ・一定量まとめて移動させる。 ・Hourly、Daily、Weekly、Monthly等の周期で動かす。 |
| ニアリアルタイム (変更データキャプチャ) | 短い | ・CDCと略される場合がある ・変更データセットを監視し、差分を連携する。 |
| ニアリアルタイム (イベント駆動) | 短い | ・ファイルが配置される、またはイベント通知をトリガーに動作する。 ・順番は保証されないことが多い ・エンタープライズ・サービスバスを利用して実装されることが多い |
| ニアリアルタイム(非同期) | 短い | ・データ受信側の確認を待たずに提供側が処理を続行する。 ・独立性を意識する(疎結合にする)目的で利用することが多い |
| リアルタイム(同期) | 極めて短い | ・遅延や相違を許さないケース(同一トランザクション内で処理) ・一般的に整合性は保証される |
| リアルタイム(ストリーミング) | 極めて短い | ・イベント発生したときにリアルタイムに連続して流れる。 |
レプリケーション
サービスによっては、世界中に展開され低レイテンシーに提供するため、あるロケーションの更新を他のロケーションに物理的にコピーすることがあります。これにより各ロケーションに展開されたサービスのクエリでパフォーマンス低下を最低限におさえられます。
このコピーは、通常はデータセット自体をコピーするのではなく更新ログを監視しニアリアルタイムで連携する事が多いです。(上述したCDCと同じ仕組み)
アーカイブ
利用頻度が低いデータは、コストが掛からない形で代替データ構造やストレージソリューションにETLで移行することがあります。
昔はETLで移行していましたが、クラウドのストレージサービスの機能を利用することでETLを利用することもなくアーカイブストレージに、移行することが簡単にできます。
エンタープライズ・メッセージフォーマット/カノニカルデータモデル
組織あるいは、データ交換グループがデータを共有するためにフォーマットを標準化するのがカノニカルデータモデルです。
ハブ&スポーク型を採用したデータ連携の設計パターンでは、データを提供・受信する全てのシステムは中央の情報ハブとのみ対話します。共通メッセージフォーマットやエンタープライズ・メッセージフォーマット(カノニカルモデル)にもtづいて、送信と受信のシステム間で変換されます。
これにより、データを交換するシステムや組織が必要とするデータ変換の数が抑えられます。各システムは、データを交換したい中央のカノニカルモデルとの間でのみデータを変換すれば良い。
データ連携モデル
| データ連携モデル | 特徴 | メリット/デメリット |
|---|---|---|
| ポイント・ツー・ポイント | システム間で直接データを連携する | メリット ・SPOFが生まれにくい デメリット ・システムが増えるにつれてインタフェイスの管理が効率が悪くなる。 |
| ハブ&スポーク | ・中央データハブへ共有データ(物理的・仮想的)を集約する。 ・中央の共通システムを介してデータを交換する。 ・DWH、データマート(DM)、オペレーショナルデータストア、マスタデータ管理などが代表例である。 | メリット ・データソースにアクセスする必要があるシステムと抽出の数を最小限に抑え、ソースシステムに対する影響を低減できる ・システム間の連携を抑えることができ、インタフェイスの管理効率が増す デメリット ・SPOFになりやすい ・高いパフォーマンスを求められる |
| パブリッシュ・サブスクライブ | ・Push(パブリッシュ)するシステムとPull(サブスクライブ)がある。 | メリット ・結合度が低いため、パブリッシュ側が影響を受けづらい。 ・複数のPullシステムが同一フォーマットでデータを受け取ることができる。 デメリット ・構成が複雑になりやすく開発コストがかかる |
データ統合と相互運用性の概念
カップリング
カップリングとは2つのシステムが関連しあっている結合度合いを指します。
密結合された2つのシステムは他方のシステムシステムからの応答を待機する同期インタフェイスを備えています。密結合は、一方のシステムが利用できないときに、結果的に双方とも利用できなくなります。そのため、両方の対象業務の継続性も計画する必要があります。
オーケストレーションとプロセスコントロール
オーケストレーションとは、複数のプロセスがシステム内でどのように構成され、実行されるかを表したものです。
このプロセスの順序は、一貫性と継続性が保たれるように管理される必要があります。
エンタープライズアプリケーション統合(EAI)
エンタープライズアプリケーション統合モデル(EAI)でソフトウェアモジュールは明確に定義されたAPIだけを介して連携します。
データストアは、独自のソフトウェアからのみから更新され、他のソフトウェアはアプリケーション内のデータに到達することは出来きません。
エンタープライズ・サービスバス(ESB)
システム間の仲介役として、システム間でメッセージやファイルをやり取りするシステムです。
サービス指向アーキテクチャ(SOA)
アプリケーション間で定義されたサービス呼び出しを利用することで、データを提供したり、データを更新したりする機能を備えます。他のアプリケーションの内部構造は隠蔽されており独立性が確保されています。
インタフェイスを持つシステムに大きな変更を加えずに、システムを置き換えることが可能になります。下記のような技術を用いて実装されます。
- Webサービス
- メッセージング
- RESTful API
複合イベント処理(CEP: Complex Event Processing)
イベント処理の定義は、発生した事象(イベント)に関する情報(データ)の流れを追跡し分析(処理)し、そこからある結論を引き出す手法です。
CEPは、複数のソースから得られるデータを結合してイベントを識別し、下記のような処理を行います。
- レコメンド
- 不正検知
複合イベントを処理するサポートするにには様々な種類の膨大なデータを統合できる環境を必要です。
データフェデレーションと仮想化
異なるデータストアにデータが存在する場合でも、物理的な統合以外の方法でデータを統合できます。
例えば、AWSのAthenaのようにフェデレーション機能を有しているクラウドサービスがあります。

データ・アズ・ア・サービス(DaaS)
ベンダーがライセンス提供し、必要に応じてデータを提供する形態があります。
クラウドベースの統合
下記のユースケースに対応するクラウドサービスとして提供されるシステム統合の一形態です。
- データ
- プロセス
- SOA
- アプリケーション統合
データ交換標準
Data Exchange Standardは、データエレメントの構造に関する正式なルールです。
データ交換の仕様は、データ共有書式を標準化する組織や交換グループによって利用される共通モデルです。データ変換用の構造を定義しています。これにより下記のメリットがあります。
- 相互運用性の簡素化
- サポートコスト
- データの理解が深まる
NIEMは、National Information Exchange Modelの略称であり、米国政府機関の間でドキュメントやトランザクションを交換するために開発されました。これにより共通かつ明確な理解を共有することが出来ました。NIEMに適合することで、相互運用性が確保されます。
活動内容(アクティビティ)
データ統合と相互運用性のアクティビティは、下記の開発ライフサイクルに従います。
- 計画と分析
- 開発
- テスト
- 実装と監視
実装後は、統合されたシステムを管理し、監視し、強化する必要があります。
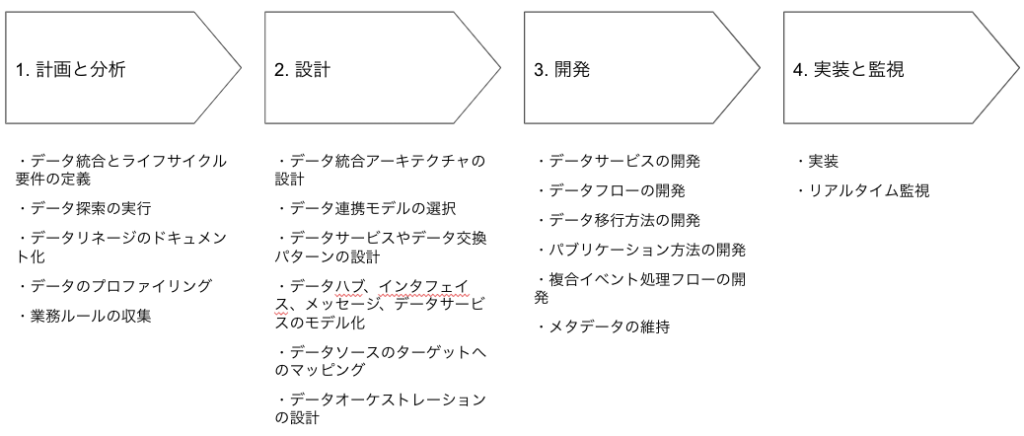
計画と分析
| アクティビティ | 目的 | 実施項目 |
|---|---|---|
| データ統合とライフサイクル要件の定義 | 業務アナリスト、データスチュワード、アーキテクトの共有を整理し要件化する。 | ・業務上の目的を理解 ・技術的取り組みを理解 ・利用するデータに関する法律や規制を収集 |
| データ探索の実行 | ・データ統合のための潜在的なデータソースを特定する。 | ・データの取得場所と統合場所を特定 ※実施方法は、ドキュメントやデータセットを調査する ・データ品質の概略を評価し、目的にデータが適合しているか確認 |
| データリネージのドキュメント化 | データがどのように流れるかについて明らかにする | ・ドキュメントやコードを確認 |
| データのプロファイリング | ・データ品質を評価すること ・データの内容と構造を理解することで、実装やテストの段階で問題が顕在化するのを防ぐ | ・ドキュメントと、実際のデータの乖離を確認 ・入力されたNULL、空白、初期値の確認 ・データ値が規定の有効地の集合とどれだけ乖離しているか ・データセットに内在するパターンとリレーションシップ |
| 業務ルールの収集 | 要件を構成する一部のため、要件との整合性を確認する。 | 業務ルールを下記に分類する ・業務用語の定義 ・用語を相互に関係づける事実 ・制約や実行条件 ・導出 |
設計
データ統合ソリューションは、導入のコストを削減するため「データアーキテクチャ」で検討したものをなるべく再利用します。
| アクティビティ | 解説 |
|---|---|
| データ統合アーキテクチャの設計 | 下記から、要件を満たす連携モデルやその組み合わせを決定する。 ・ハブ&スポーク ・ポイント・ツー・ポイント ・パブリッシュ・サブスクライブ データサービスやデータ交換パターンの設計 |
| データハブ、インタフェイス、メッセージ、データサービスのモデルの設計 | 下記のモデルを設計します。 永続的 ・マスタデータ管理ハブ ・DWHとデータマート ・オペレーショナルストア 一時的 ・インタフェイス ・メッセージレイアウト ・カノニカルモデル |
| データソースのターゲットへのマッピング | ソースからターゲットへの変換マッピングを定義する。 下記に定義するポイントを記載する。 ・ソースとターゲットの技術的フォーマット ・必要な変換内容 ・データをロードする方法 ・値を変換する必要があるか ・演算内容 |
| データオーケストレーションの設計 | リアルタイム型とバッチ型で異なる。 |
開発
下記の開発を行います。
- データサービスの開発
- データアクセス、変換、配信するサービス。
- データフローの開発
- データ移行方法の開発
- プロファイリングの結果を踏まえて移行アプリケーションを作成します。
- パブリケーションの開発
- 他のシステムへのデータを連携した後に、通知を行う仕組みを実装します。
- 複合イベント処理フローの開発
- ドキュメントの維持
実装と監視
開発し、テストが済んだサービスを稼働させます。それに伴い監視を開始します。
ツール
ここでは、データ統合と相互運用性で登場するツールの種別を紹介します。
| ツール | 解説 |
|---|---|
| データ変換エンジン/ETLツール | 検討のポイント ・リアルタイム 、バッチに適したETLツール ・構造化、非構造化 |
| データ仮想化サーバ | データの抽出・変換・統合を仮想的に行う。 |
| エンタープライズ・サービスバス | ソフトウェアアーキテクチャモデルとメッセージ思考のミドルウェアの両方を指す。 同じ組織内に存在する異なる種類のデータストア、アプリケーション、サーバ間でニアリアルタイムでメッセージングを実装するために利用する。 |
| 業務ルールエンジン | 多くのデータ統合ソリューションは業務ルールに依存している。 基本的な統合や複合イベント処理を組み込んだソリューションで利用される。 |
| データとプロセスのモデリングツール | ソースとターゲットの間を結ぶための中間データの構造をモデリングする |
| データプロファイリング・ツール | データ統合と相互運用性の開発には、実際のデータが考慮中のソリューションが持つニーズを満たすかどうか判断するために、プロファイリングツールを利用する。 |
| メタデータリポジトリ | 様々な運用ツールからデータを整理統合できる |
導入ガイドライン
組織と文化の変革
組織では、データ統合の管理責任を判断する必要があります。多くの場合は組織横断の専門チームを利用しています。
| 組織形態 | 特徴 |
|---|---|
| 組織横断的な専門チーム | ツールや使用技術に関する深い知識を蓄えることが出来る |
| アプリケーションチームに担当 | データを把握している |
データ統合ソリューションでは、技術的なものとして認識されることが多くあります。しかし適切な価値を提供するためには、深い業務知識が必要になる点を留意しておく必要があります。
ガバナンス
データ共有合意
1.データ共有合意の作成
インタフェイスの開発やデータ提供に先立ち、交換されるデータの責任と許容される利用法を規定するデータ共有合意や、覚書を作成します。下記にデータ共有合意の内容を記載します。これらは、個人情報など含まれる場合において重要です。
- 必要なシステム稼働時間、応答時間を含む期待されるサービスレベル
- 予想される利用法とデータへのアクセス
- 利用制限
2.上記の文章はデータスチュワードによって承認されます。
データ統合とデータリネージ
下記の理由から、データリネージが必要になります。
- データが移動する過程で統合や変換などが発生します。データの発生元と移動に関する知識がまとまっている必要があります。
- データの共有合意の利用制限を遵守するためにはデータがどこに移動して、どこに保存されるか知る必要があります。このようなリネージを企業が説明できるように義務付ける法律もあります。
- データ変更に加えるときの影響分析
データ統合の評価尺度
統合ソリューションの実施規模とメリットを測定するには、下記のようなメトリクスを取得します。
| カテゴリ | メトリクス |
|---|---|
| データ可用性 | 要求されたデータの可用性 |
| データの量と速度 | 転送され、変換されたデータの量 |
| 分析されたデータの量 | |
| 伝送速度 | |
| データ更新と可用性の間のレイテンシ | |
| イベントと起動されたアクション間のレイテンシ | |
| 新しいデータソース利用開始までの時間 | |
| ソリューションのコストと複雑さ | ソリューションの開発と管理コスト |
| 新しいデータを取得するときの容易さ | |
| ソリューションと運用の複雑さ | |
| データ統合ソリューションを利用するシステム数 |
最後に
今回の記事では、「データ統合と相互参照性」を解説しました。
普段、なにげなくETLを作っていましたが、あらためて知識を整理することで無意識に取り組んでいた内容が言語されました。
いきなりこのような知識から入っても頭に入りづらいので、一度簡単なアプリケーション等を作成してから読むのがお薦めです。
本記事が皆様のお役に立てれば幸いです。
今回も読んで頂きましてありがとうございました。


コメント