
Apache Sparkについて学びたいけど、どこから始めたらいいのかわからないと感じている初心者の方向けに書きました。基本的な概念から応用的なテクニックまで、ステップバイステップでわかりやすく解説します。これを読めば、Sparkの世界がぐっと身近に感じられると思います。
- Apache Spark初心者: Sparkに興味はあるが、何から始めたらよいかわからない人。
- データエンジニア・データサイエンティスト: データ処理のスキルを高めたいと考えているが、Sparkについてはまだ詳しくない人。
- 学生・研究者: 学術研究やプロジェクトでSparkを使用する可能性があるが、基本から学びたい人。
- システムエンジニア・開発者: 既存のシステムにSparkを統合したいと考えているが、そのメリットや方法について知りたい人。
- ビジネスアナリスト: データ解析のためにSparkの概要を理解したい人。
- 基本的な理解: Sparkの基本概念とコンポーネントについての理解が深まります。
- 応用知識: より高度なテクニックやユースケースについても学べるため、即戦力として活躍できます。
- ステップバイステップの学習: 記事がステップバイステップで構成されているため、初心者でも無理なく学べます。
- 自信の向上: Sparkについての基本的な知識から応用までを網羅しているため、自信を持ってプロジェクトに取り組むことができます。
たくさんの用語がでてくるSparkの用語について、内部の動作を含めて解説していきます。
Sparkとは?:初心者向け!Apache Sparkの基本特徴を解説
Apache Sparkは、大量のデータを効率よく処理するためのオープンソースの分散コンピューティングフレームワークです。Apacheソフトウェア財団の主要プロジェクトとして広く採用されています。以下に、Sparkの主な特徴を簡単に列挙します。
- 高速な処理: メモリ内でのデータ処理が可能なため、非常に高速です。
- 多言語対応: Python、SQL、Scala、Java、Rなど、複数のプログラミング言語をサポートしています。
- ANSI SQLのサポート: 標準的なSQLクエリが利用できるため、データベース操作が容易です。
- 機械学習ライブラリ: 組み込みの機械学習ライブラリを使用して、高度なデータ分析が可能です。
Map ReduceとSpark:初心者向け!課題と特長を比較解説
大規模なデータ処理においてよく用いられるHadoopのMap Reduceと、その代替手段として注目されるApache Sparkについて、それぞれの課題と特長を以下に簡潔にまとめます。
Map Reduceの課題
- 性能: Map Reduceはディスクに中間データを保存するため、ディスクI/Oが処理速度のボトルネックになることがあります。
- 柔軟性: MapとReduceの二つのフェーズで構成されており、その制限内でプログラミングする必要があります。
- 学習コスト: JavaやPythonでジョブを記述する必要があり、初心者にとっては学習コストが高いです。
Sparkの特徴
- 性能: Sparkはメモリ内での処理が可能なため、高速です。
- 柔軟性: 複数の処理ステージを設定でき、複雑なデータ処理パイプラインも構築可能です。
- 使いやすさ: Java、Scala、Rなど多くの言語をサポートしており、さまざまなライブラリが用意されています。これにより、エンジニアだけでなくデータサイエンティストにも使いやすいとされています。
初心者向け!Sparkの多様なユースケースを解説
Apache Sparkはその高性能と柔軟性から、多くのデータ処理のシナリオで使用されています。以下に、主なユースケースをいくつか紹介します。
- バッチ処理: 大量のデータを一括で処理する場合によく用いられます。例えば、日次や月次のレポート生成など。
- ストリーミング処理(リアルタイム処理): データがリアルタイムで生成される場合、そのデータを即座に処理する用途で使われます。例としては、リアルタイムのダッシュボードやアラート生成など。
- データサイエンス、機械学習: Sparkは高度なデータ解析と機械学習ライブラリを提供しており、データサイエンティストや研究者によく使用されます。
- 分析: Spark SQLを用いて、大量のデータに対して高速なデータ分析が可能です。
初心者にもわかる!Sparkコンポーネントの基本構造
Apache Sparkのアーキテクチャはいくつかの主要なコンポーネントで構成されています。具体的には、Driver Program(通称:Driver)、Worker Node内のExecutor、そしてCluster Managerです。この章では、これらのコンポーネントがどのように連携して動作するのか、初心者でも理解できるように詳しく解説します。
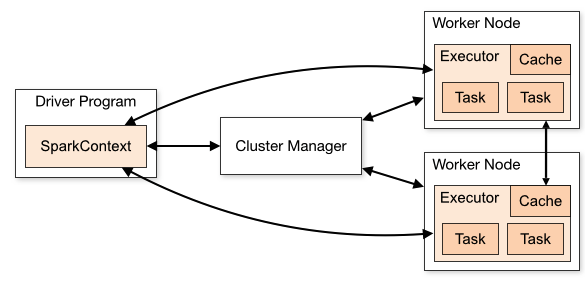
※出典 : Cluster Mode Overview > Components
Driver Program(Driver)
Driverは、上記の図で左にあるDriver Programを指しています。Driverは、ユーザが作成するプログラムのmain関数を実行し、Executorを管理します。
- Driverは、SparkContext(SparkSession)を生成し、Sparkを実行・管理します。
- Driverは、ユーザプログラムをSparkで実行の単位(タスク)に変換します。タスクは、Sparkで実行される最も小さい単位です。(後述)
- Executor上のタスクをスケジュールします。Executorプロセスは起動時に自分自身をDriverに対して登録します。これにより、DriverがExecutorの管理が可能になります。
Executor
Executorは、上記の図の右側にあるWorker Node内のプロセスになります。タスクを実行しデータを保持する事ができます。
- Sparkジョブの個々のタスクの実行を受け持つワーカープロセスです。このタスクを実行し、結果をDriverに返します。
- Executorにはインメモリストレージを備えており、ブロックマネージャーと呼ばれるサービスを通じて提供します。
Cluster Manager
Cluster Managerは、上記の図の中央になります。各Worker Nodeのリソース状況を管理し、Driverからのリクエストに応じて、必要なリソースをアサインします。
Cluster Managerには、下記が選択可能です。
- Standalone
- Apache Mesos
- YARN(Apache Hadoop YARN)※こちらの記事でもYARNを取り上げています。よろしければご確認ください。
- Kubernetes
Sparkのソフトウェアスタック:初心者向けに各レイヤーを解説
Apache Sparkは、複数のソフトウェアレイヤーで構成されています。最も基本的な部分は「Spark Core」と呼ばれる実行エンジンです。このエンジンを基盤に、さまざまな高度な機能が提供されています。
- Spark Core: これがSparkの心臓部であり、基本的なデータ処理と分散処理の機能を提供します。
- 最適化層: ここではCatalyst OptimizerやDataFrameが活躍します。これらのコンポーネントは、Spark Core内のRDD(Resilient Distributed Dataset)を効率よく処理するための最適化を行います。
- 上位レイヤー: SparkSQLや各種プログラミング言語(Python、Scalaなど)がこのレイヤーで利用されます。これにより、多様なデータ処理が可能になります。

Sparkのデータの流れ:初心者向けにRDDからパーティションまでを解説
Apache Sparkでは、データ処理の基本単位として「RDD(Resilient Distributed Dataset)」が用いられます。このRDDは、複数のWorker Node(Executor)に分散して配置される「パーティション」として実際には存在します。
- RDD(Resilient Distributed Dataset): これはSparkが扱うデータの基本形です。プログラミングではこのRDDを操作します。
- パーティション: RDDは、各Worker Nodeにパーティションとして分散されます。これにより、データは並列に処理され、高速な計算が可能になります。
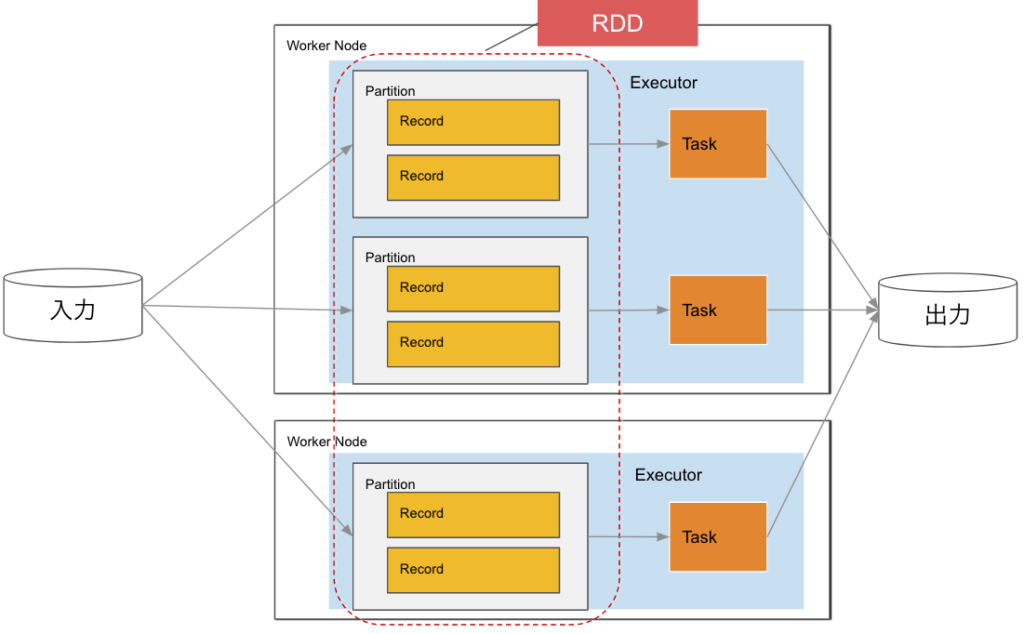
Sparkのパーティション
パーティションとは
Sparkでは、データセットをパーティションという単位に分割してメモリで管理します。データセットは、RDDとして管理され、一定のチャンク(塊)であるパーティションとして各ノードに分散され下記の特徴を持ちます。
- 各パーティションはExecutor内のタスクで処理されます。
- パーティションとタスクは1:1の関係になります。
パーティション分割と、分割のロジック
データセットが分割されたパーティションは、下記のロジックで分割されます。
- パーティション数
- Sparkのパラメータ、実行環境等でパーティション数が決まります。
- パーティションへのデータ配置
- パーティションへのデータ分散は、パーティショナーで決まります。標準では下記の2つが選択が可能です。また、独自のパーティショナーも作成が可能です。
- HashPartitioner
- キーで均一に分散されます。デフォルトではこちらが採用されます。
- RangePartitioner
- 特定のレンジに基づいて分散されます。
- HashPartitioner
- パーティションへのデータ分散は、パーティショナーで決まります。標準では下記の2つが選択が可能です。また、独自のパーティショナーも作成が可能です。
分割のタイミング
下記のタイミングで分割されます。
- データ読込時
- シャッフル時
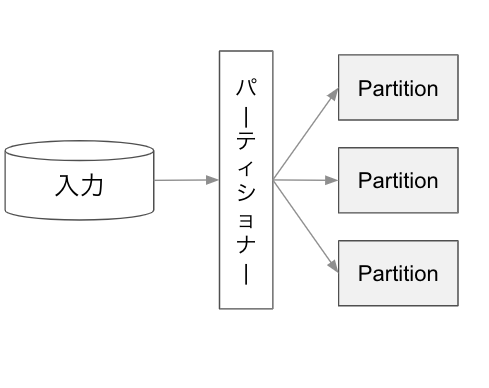
1.データ読込時
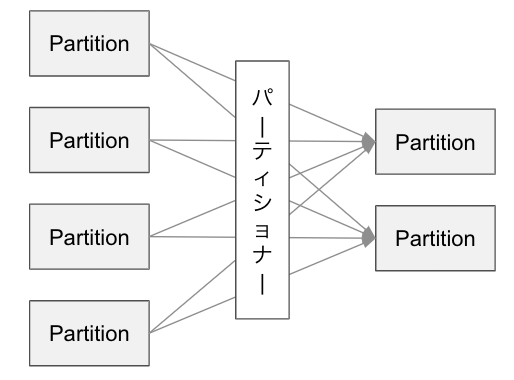
2.シャッフル時
1.データ読込時のパーティション分割
Sparkのパーティショナーは、データを読み込む際に、下記を元に分割するパーティション数を決定します。※下記の1で条件を満たさない場合、分割されません。
- 分割可能なファイルフォーマットか?下記のフォーマットであれば分割は可能です。
- JSON
- Parquet
- ORC
- Sparkのプロパティ(spark.sql.files.maxPartitionBytes)の値
- データ読み取り時に、一つのパーティションに詰め込む最大バイト数
- デフォルトでは128MiB
※参考 Spark > Performance Tuning > Other Configuration Options
2.シャッフル時のパーティション分割
Sparkでは、シャッフルを伴う処理を実行した際に、各パーティションから必要なデータを収集し、新しいパーティションに結合します。Sparkではこのシャッフルという処理は、分散されたパーティションのデータを横断的に交換するため、比較的高いコスト(負荷が高い)になるため注意が必要です。
下記の1のシャッフルを伴う変換が行われた場合に、Sparkのパーティショナーは2)のプロパティを使用してパーティション数を決定します。
シャッフルを伴う処理の例
- join()
- groupBy()
- orderBy()
- repartition()
シャッフルを伴わない処理の例
- read
- filter()
- withColumn()
- UDF()
- coalesce()
明示的に分割する方法
データの偏りが大きく、一部のタスクだけ処理時間が長い場合や、全体的にタスクの並列数を増やして高速介したい場合など、パーティションを再配置を行い調整します。
再配置には、 DataFrameのrepartitionと、coalesceを使用します。
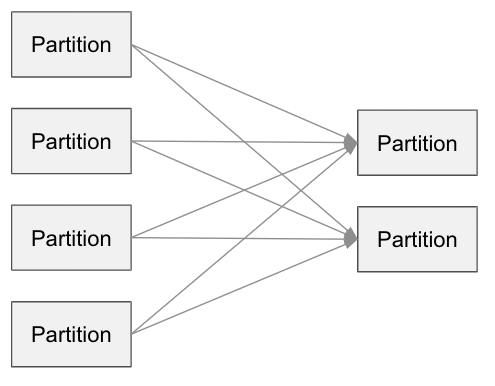
repartition
パーティションを横断的に再配置します。シャッフルが発生します。
df.repartition(2)
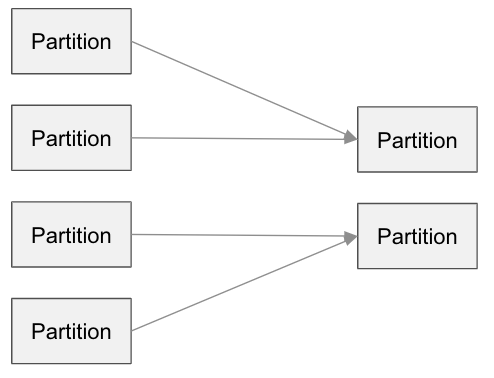
coalesce
Executor内のパーティション間で再配置します。シャッフルは発生しません。
df.coalesce(2)
Sparkプログラミング
RDDとDataFrame、Dataset
いずれも分散コレクションです。当初はRDD(2011年)のみでしたが、DataFrame(2013年)、Dataset(2015年)と追加されています。なお、Datasetは型のチェックを行いますが、Pythonでは型がありませんので、Python(PySpark)ではDatasetは利用できません。
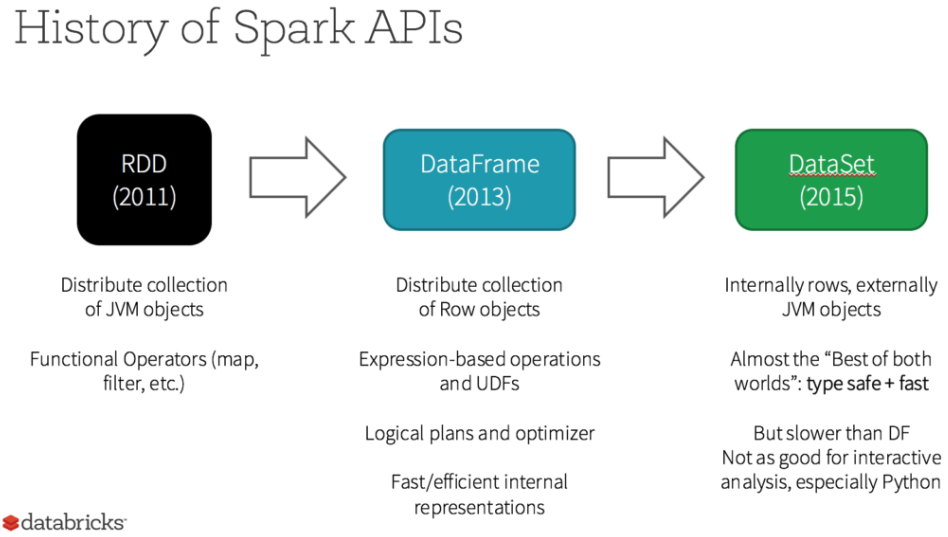
出典:Databricks > 耐障害性分散データセット(RDD)
RDD
RDDは、Resilient Distributed Dataset の略です。クラスタのノードを横断して分割された並行して操作されることができる分散コレクションです。基礎的なAPIを提供します。DataFrameやDatasetが利用できるバージョンにおいて、DataFrame、Datasetだけでは対応できない低レベルの変換、アクションなど実行する場合にRDDを使用します。
DataFrame
DataFrameは、スキーマを定義できる分散コレクションで下記の特徴があります。
- 表形式のデータ構造のイメージに近く高次元なAPIを提供
- SparkSQLが利用できる。簡単なコードでDataFrameをRDBのテーブルのように利用できます。
- 性能面でRDDよりも優れている。DataFrameはアクション時に、Catalyst Optimizer(後述)により最適化されRDDよりも高い特徴があります。

※出典 Databricks > Introducing DataFrames in Apache Spark for Large Scale Data Science
Dataset
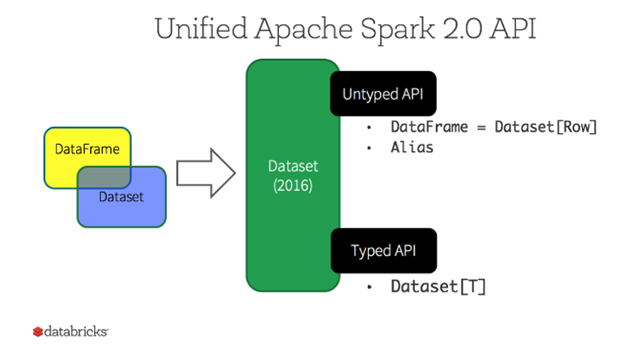
Datasetは、Java、Scala用の構造化APIのタイプセーフなAPIです。利用者はJavaクラスをDataFrame内のレコードに割り当てて、JavaのArrayListやScala Seqと同様に型付きオブジェクトのコレクションとして扱えます。最初に定義したデータセット内のオブジェクトを、別のクラスとして扱うことはできないため、タイプセーフです。
DatasetAPIは、下図のようにUntyped APIとTyped APIの2種類があります。
Catalyst Optimizer
Spark SQL の中核をなす機能です。ロジック最適化、物理プランニング、Javaのバイトコード生成などクエリ実行までにいくつかのフェーズがあります。またルールベースとコストベースをサポートしています。Catalyst Optimizerは下記の目的を想定して設計されています。
- Spark SQLへの最適化技術と昨日の追加を容易にする
- 外部の開発者でもOptimizerを拡張できるようにする。(データソース特有のルール追加や、新規データ型のサポート等)
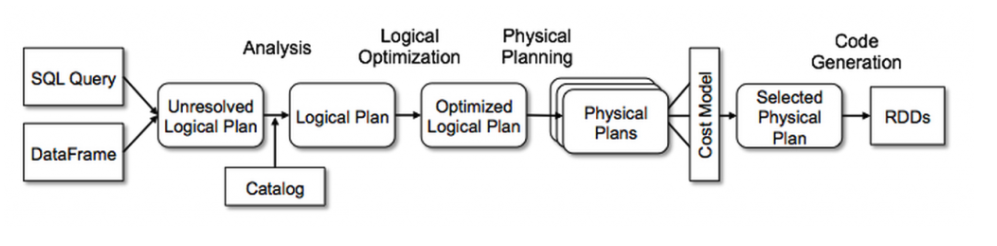
※出典 Databricks > Catalyst Optimizer
- Catalyst Optimizerは下記の4つのフェーズを有します。
- Analyticsフェーズ
- DataFrameのクエリなどの抽象構文木を生成
- この段階でカラムやテーブル名は内部カタログを参照して、解決される。
- Logical Optimizationフェーズ
- 2つの内部ステージにより構成される。
- 標準的なルールベースの最適化アプローチにより、複数のプランを構築
- CBO(Cost Base Optimizer)により各プランにコストを割り当てる。
- 2つの内部ステージにより構成される。
- Physical Planning
- 選択したLogical Planに対して最適なPhysical Planを生成する。
- Code Generationフェーズ
- 各マシンで実行するための効率的なJavaバイトコードを生成する。
- Project Tungstenにより、全段コード生成※1する。
- Analyticsフェーズ
クエリ全体を単一の関数に折り畳み、仮想関数呼び出しを排除し、中間データにCPUレジスタを採用する物理的なクエリ最適化を行うものです。
Sparkアプリケーション:Sparkジョブ:Sparkステージ:タスク、パーティションの関係
Sparkには、実行の単位としては、アプリケーション、ジョブ、ステージ、タスクという概念があります。

- アプリケーション
- SparkContext、またはSparkSession単位に作成するユーザプログラム
- ジョブ
- アクション単位(後述)で作成される。(分割される)
- ステージ
- シャッフル単位(後述)で作成される。(分割される)
- タスク
- 実行の単位。Executerに展開される。map、shuffle、reduce、sortなどの種類がある。
アプリケーションとジョブ
Sparkアプリケーションは、複数のジョブから構成されます。上述した通りジョブは、アクション単位で作成されます。
conf = SparkConf().setAppName("sample application").setMaster(master)
sc = SparkContext(conf=conf)
df1 = sc.read.json("入力ファイルパス")
df1.show() #ジョブ1
df1.fiter(df1.col1='a').write.parquet("出力ファイルパス") #ジョブ2
変換とアクション
変換は、データを読み込みDataFrame等を生成したり、生成したDataFrameに対して、加工や集計などを行います。また、アクションは、ストレージへの書き出しやドライバの標準出力処理を行います。
変換:データの生成や加工処理
- select()
- read
- filter()
- groupBy()
- sort()
アクション:処理結果の出力
- count()
- write()
- collect()
- show()
- describe()
ステージ
シャッフル単位でステージがわかれます。1つのステージで複数のタスクが並行処理されます。
遅延評価
Sparkアプリケーションの特徴の1つとして、遅延評価があります。遅延評価はSparkアクション時に必要な前段の処理を全て行われます。アクションによって実行される一連の処理のまとまりは、上述したジョブになります。
df1 = spark.read.csv("入力ファイルパス")
df2 = spark.read.json("入力ファイルパス")
df3 = df1.filter(df1.col1='a')
df4 = df2.join(df3, df3.col1=df2.col1)
df4.count() #このタイミングで上記の処理が実行されます。永続化(キャッシュ)
Sparkでは、メモリ内のデータセットを永続化することが可能です。キャッシュされたデータセットを他のアクションの中で再利用することで、複数回再計算されるこを防ぐことができます。キャッシュ関連のメソッドは下記のとおりです。
cache()
persist("ストレージレベル")
unpersist()- cacheは、persistのMEMORY_ONLYを指定した内容と同様です。
- unpersistを使用することで、キャッシュされたデータセットを明示的に解放します。
- persistに指定するストレージレベルは下記のとおりです。
| ストレージレベル | 領域の使用量 | CPU負荷 | 格納場所 |
|---|---|---|---|
| MEMORY_ONLY | 多い | 低い | メモリ(JVM) ※ RDDがメモリに収まらない場合、一部のパーティションはキャッシュされないため、必要になるたびにオンザフライで再計算される。 |
| MEMORY_AND_DISK | 多い | 低い | メモリとディスク ※ RDDがメモリに収まらない場合は、ディスクに収まらないパーティションを保存し、必要なときにディスクから読み取る。 |
| MEMORY_ONLY_SER | 少ない | 高い | メモリ(JVM) |
| MEMORY_AND_DISK_SER | 少ない | 高い | メモリとディスク |
| DISK_ONLY | 少ない | 高い | ディスク |
最後に
今回の記事では、「Sparkの基本」として、コンポーネントやアーキテクチャなど解説しました。
Sparkは、大規模分散処理を行うフレームワークです。Hadoopよりも高速で様々なワークロードに対応できます。ETLではクラウドサービスや、オンプレミス問わずデファクトスタンダードといえます。
これからデータエンジニアを始める方、IT業界に進もうとされている方のはじめの一歩になれば幸いです。
今回も読んで頂きましてありがとうございました。


コメント