
この記事では、Hadoopとは何か?Hadoopの特徴、仕組みについて簡単に解説します。
- Hadoopとは何か知らない方
- Hadoopの特徴やアーキテクチャ・挙動を学びたい方
- Hadoopの特徴や機能がわかる
- Hadoopエコシステムの全体像がわかる
- Hadoopのアーキテクチャがわかる
Hadoopとは?(Hadoopの特徴)
Hadoopは、Apacheのトッププロジェクトの一つで、信頼性が高く、スケーラブルな分散コンピューティングのためのオープンソース ソフトウェア(OSS)です。
下記の特徴があります。
- アプリケーションが数千ノードおよびペタバイト級のデータを処理することが可能
- コンピューターのクラスター全体で大規模なデータ セットの分散処理を可能にするフレームワークを有している
簡単に言うと、大量のデータを高速に処理するデータ基盤です。
ビックデータの課題とHadoopの役割
ビックデータの課題
昨今の通信環境の進化や、コンテンツの大容量化、IoTの普及などにより大容量で多様なデータが高頻度に生み出されています。これらのデータは、下記のような課題があります。
| 課題 | 説明 |
| ボリューム | 非常に大量なデータを処理するには、多くの計算リソースが必要になる。 |
| 多様性 | 表形式のような構造化データ、センサーデータ、テキスト等の半構造データ、 または、画像や動画メディアなどの非構造データなどが含まれる。 これらの多様な形式のデータを処理するフレームワークや、 ライブラリを備えた基盤が必要になる。 |
| 速度 | リアルタイムやニアリアルタイムに発生するデータを、 決められた時間内に逐次処理する機能が必要になる。 |
上記の3つの課題は、Volume、Variety、Velocityで3つのVと一般的に呼ばれています。
Hadoopの役割
上記の課題を解決するために、Hadoopでは、以下のような役割を持ちます。
| 役割 | 説明 |
| スケーラビリティ | 大量のデータを複数のノードに分散することで、スケーラビリティを実現し 大規模なデータセットの処理が可能。 |
| 冗長性と信頼性 | HDFS(後述)を使用して、データを複数のノードに分散保存する。 これにより、データの冗長性が高く、ノードの障害に対しても データの可用性を保つことが可能。 |
| 分散処理 | 主要なコンポーネントである、MapReduceは、大規模なデータセットを 複数のタスクに分割し、それぞれのタスクを並列に処理する。 これにより、高速な処理と分析が可能。 |
| 拡張性 | Hadoopのエコシステムには、様々な拡張ツールやライブラリがあり、 そのため、処理の要件や、環境の変化に対応するための拡張性が備わっている。 |
Hadoopのコンポーネントとエコシステム
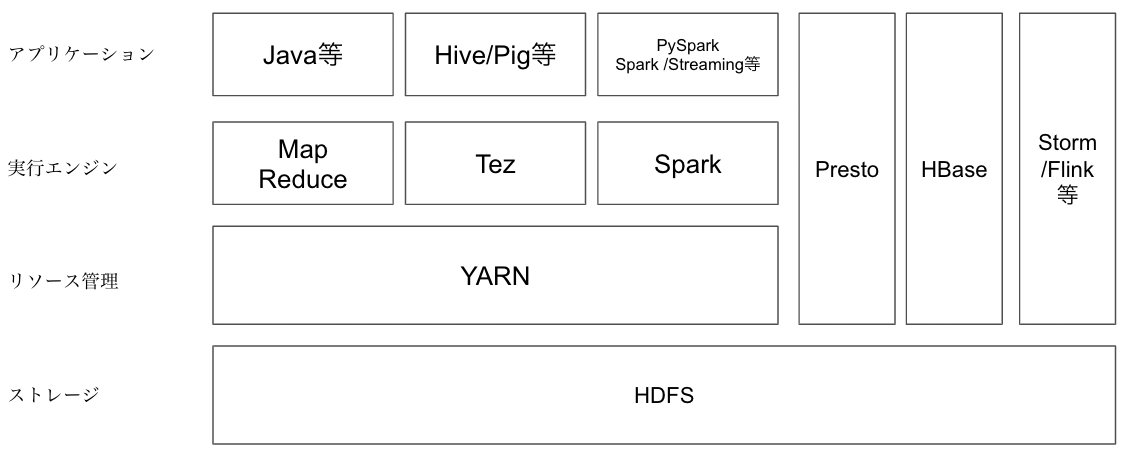
ドキュメントでは、Hadoopが主に指しているコンポーネントは、HDFS、YARN、Map Reduce、を主に指しています。これらの主要なコンポーネントのうち、ストレージのHDFSとリソース管理のYARNについては、Hadoopアーキテクチャ(後述)で詳細を解説します。
また、YARNやHDFSを利用する形で、SparkやPrestoなど実行エンジンを組み合わせて使用する事が可能であり、インタラクティブな分析やバッチ処理など、目的に応じて必要なものをインストールして使用することで、ビッグデータ処理のあらゆるユースケースに対応が可能です。
Hadoopで何ができるか(Hadoopのユースケース)
Hadoopdでは、大規模なデータセットに対して、一般的には、下記のようなユースケースが考えられます。
- ETL(バッチ処理)
- Webサイトのクリックストリームなど、Spark、Hive、Map Reduce などを使用して加工し、レポーティングや、ビジネスインテリジェンスなどのツールで利用しやすい形に整形します。
- ETL(リアルタイム処理)
- 上記のバッチ処理と同じ目的ですが、違うのは、データはファイルではなく随時ストリームデータとして流れ続けてきます。このストリームデータをFlink、Storm、Spark Streamingなどを使用して、加工・整形します。
- 分析
- Spark、Hive、Map Reduceなどを使用して、探索的にデータを分析します。
- 機械学習
- モデルのトレーニングや予測を行うために、MahoutやSpark MLlibなどのライブラリを使用します。
Hadoopアーキテクチャ
ここでは、Hadoopを構成する主要なコンポーネントのうち、HDFSとYARNについて解説します。
HDFSのアーキテクチャ
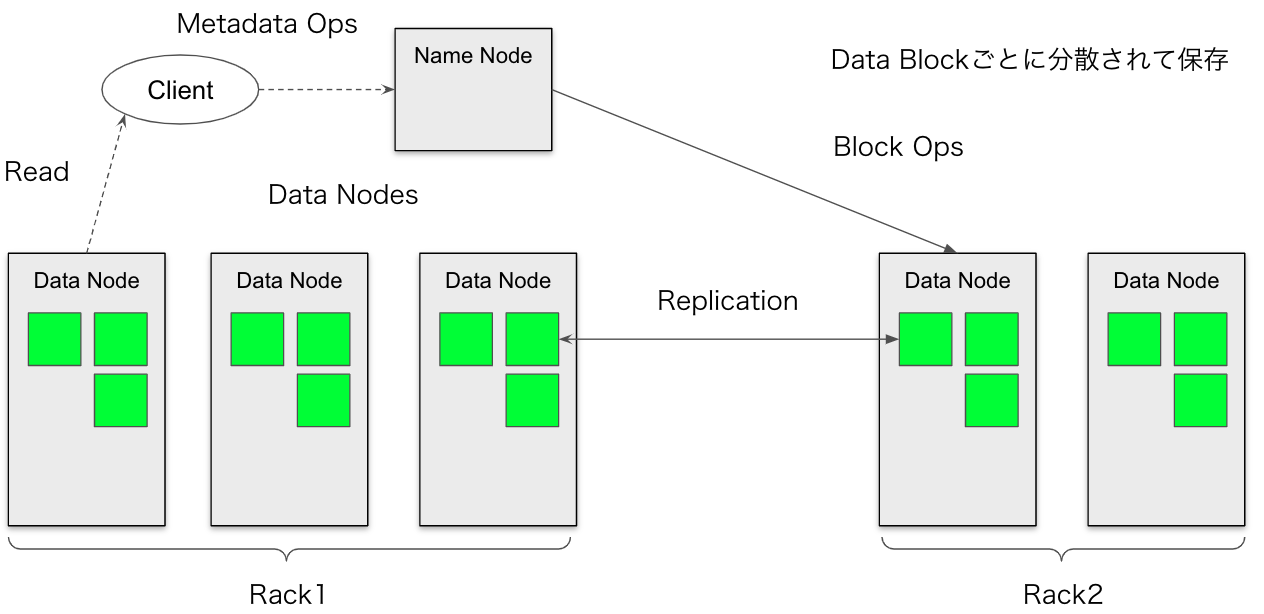
HDFSはHadoop Distributed File Systemの略です。HDFSはHadoopアプリケーションで使用される主要な分散ストレージです。HDFSクラスタは、主にファイルシステムのメタデータ管理するName Node(ネームノード)と、実際のデータを格納するDataNode(データノード)で構成されます。
HDFSのデータ読み取りの流れ
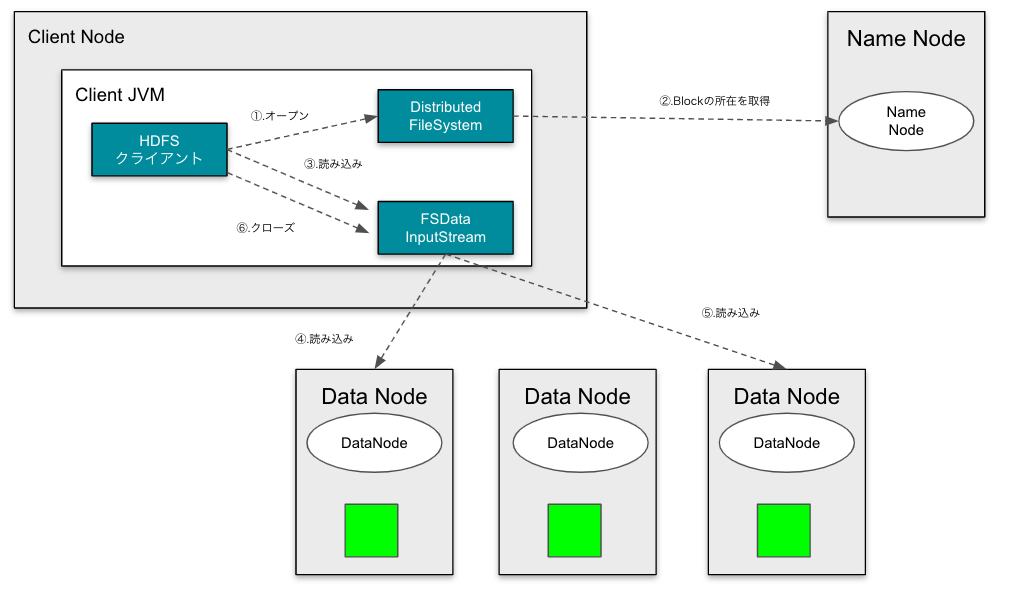
HDFSクライアントが、データを読み込む流れは下記のとおりです。
- ①〜②. 読み込みたいファイルのデータブロックの所在をName Nodeから取得します。
- ③〜⑤. 必要なデータブロックを順次読み込み、HDFSクライアントに返します。
- ⑥. クローズして終了します。
HDFSへのデータの書き出しの流れ
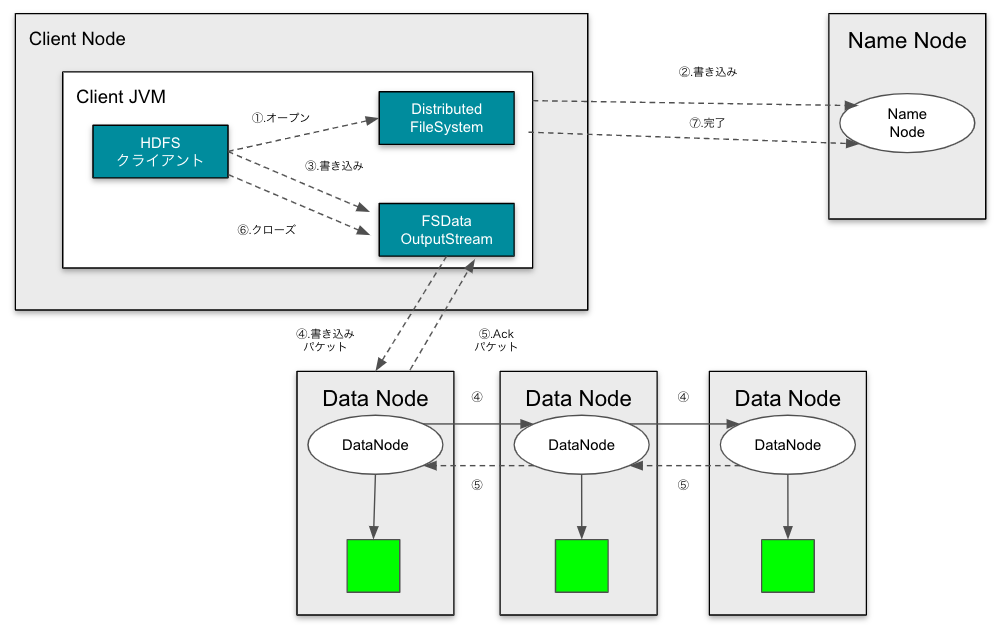
HDFSクライアントが、データを書き込む流れは下記のとおりです。
- ①〜②. 名前空間にブロックを割り当てずに、新しいファイルを生成する。Name Nodeはクライアントがそのファイルを作成するために必要なパーミッションをもっているか確認する。
- ③〜⑤. 書き込むデータをパケットに分割し、データキューと呼ばれる内部的なキューに書き込みます。レプリケーションされている場合は、全てのノードに転送されます。
- レプリケーションに途中で失敗しても、
dfs.replication.minに達していれば問題はない。後ほどdfs.replicationの数まで複製が非同期で行われる。
- レプリケーションに途中で失敗しても、
- ⑥. クローズして終了します。
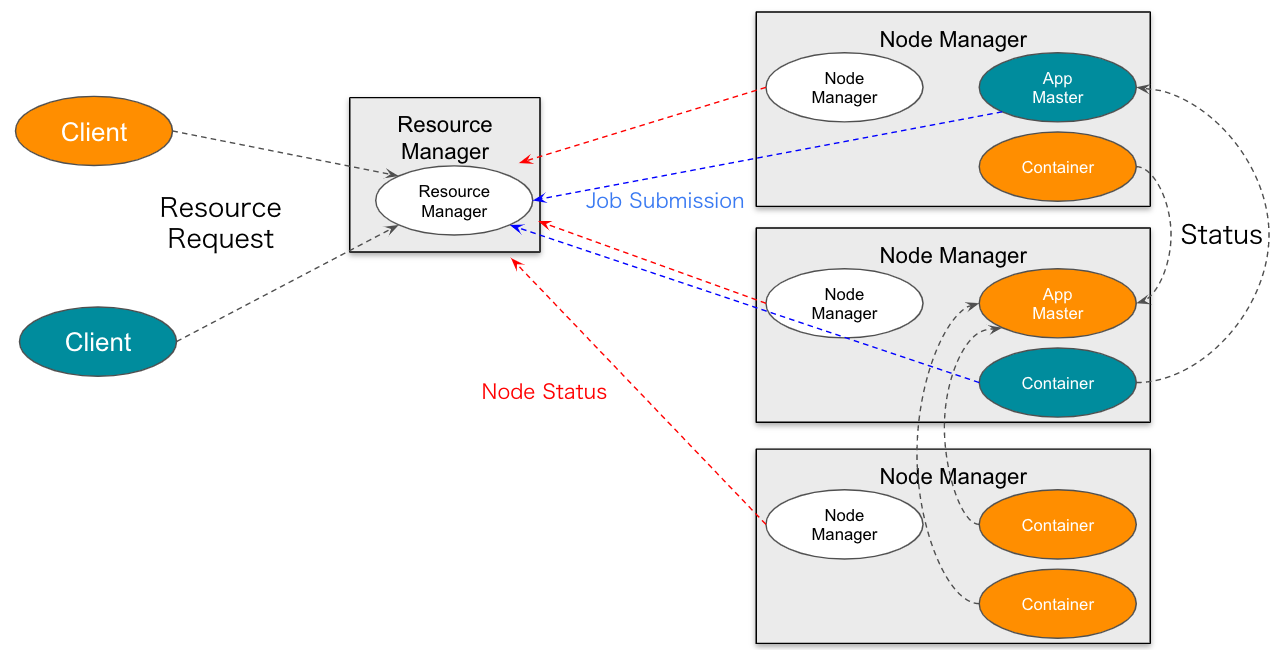
YARN
YARNは、Yet Another Resource Negotiatorの略です。YARNの基本的な考え方は、リソース管理とジョブのスケジューリング、監視の機能を別々のデーモンに分割することです。
YARNは、クラスタ全体のResourceMangerと、アプリケーションごとのApplicationMasterを持ちます。
ResourceManagerは、システム内の全てのアプリケーション間でリソースを調停する最終的な権限を有します。NodeManagerは、コンテナを担当するマシンごとのフレームワークエージェントであり、リソースの使用状況(CPU、メモリ、ディスク、ネットワーク)を監視し、ResourceManagerにレポートします。
最後に
今回の記事では、「Hadoopの基本」として、コンポーネントやアーキテクチャなど解説しました。
Hadoopは、大規模分散処理を行うフレームワークです。主に、データ管理のHDFSと並列分散処理するためのYARNが中心にあり、ここにSparkやMap Reduceなどの各アプリケーションを組み合わせて目的の処理を実行します。
最近では、クラウドベンダーが提供されるサービスにより、Hadoopそのものの仕組みを意識する必要なく比較的簡単に大規模分散処理ができるようになりましたが、分散処理や、大規模データの管理の基本を抑えておくことで、応用が効くようになると思います。
これからデータエンジニアを始める方、IT業界に進もうとされている方のはじめの一歩になれば幸いです。
今回も読んで頂きましてありがとうございました。

コメント